Explore your webpages
When you want to make a Helena program, first pick the website or websites from which you'll collect data. Look around the webpages you'll use so that you know where your information is located. For this tutorial, you'll be extracting data from
http://helena-lang.org/sample-data, so take a moment to play around with that page and its links. And remember, once you're doing a demonstration, everything that you do during the recording is also going to be done by your program; so now's the time to do any stray clicks, follow stray links, and generally figure out where your data lives.
Decide what data you want
Next decide what you want to include in your dataset - you should know exactly how your target dataset should look. Let's say we want to collect the following table:
| Scandal |
Awesome! |
| Buffy the Vampire Slayer |
Awesome! |
| Angel |
Not So Awesome |
So we want to know, for each TV show in the list, what's the title of the show and what's the extremely subjective quality rating. When we use Helena, we write a scraping program by demonstrating how we interact with the browser to collect the first row, so we'll want to demonstrate how to collect "Scandal" and "Awesome!" from the webpage. Then Helena will write a program for collecting all three rows.
Open the extension
Let's figure out how we demonstrate with Helena. Let's navigate to
http://helena-lang.org/sample-data, then open the extension. We open the extension by clicking on the icon at the upper right. This opens the control panel on the left:
And at the right, we see a new window, open to the URL we were using when we clicked on the Helena icon. This is the recoding window. Everything that we want to have recorded needs to happen in this window, because Helena isn't paying attention to any of the other Chrome windows we might have open. We recommend keeping both the control panel and the recording window visible throughout recording so that Helena can give you feedback about the data you're collecting.
Figure out what you can scrape
When you make a demonstration, your job is to show Helena how you'd collect the
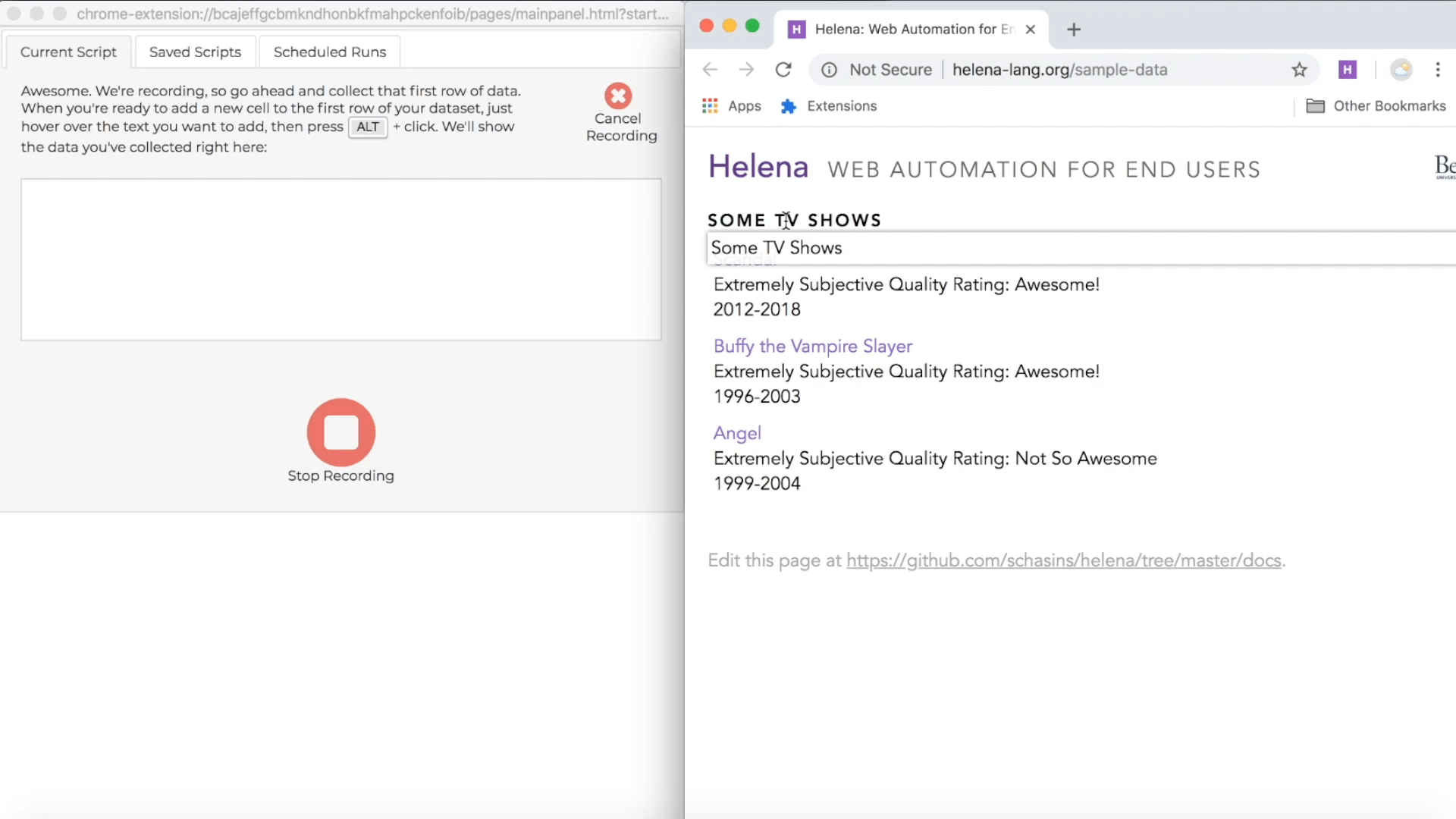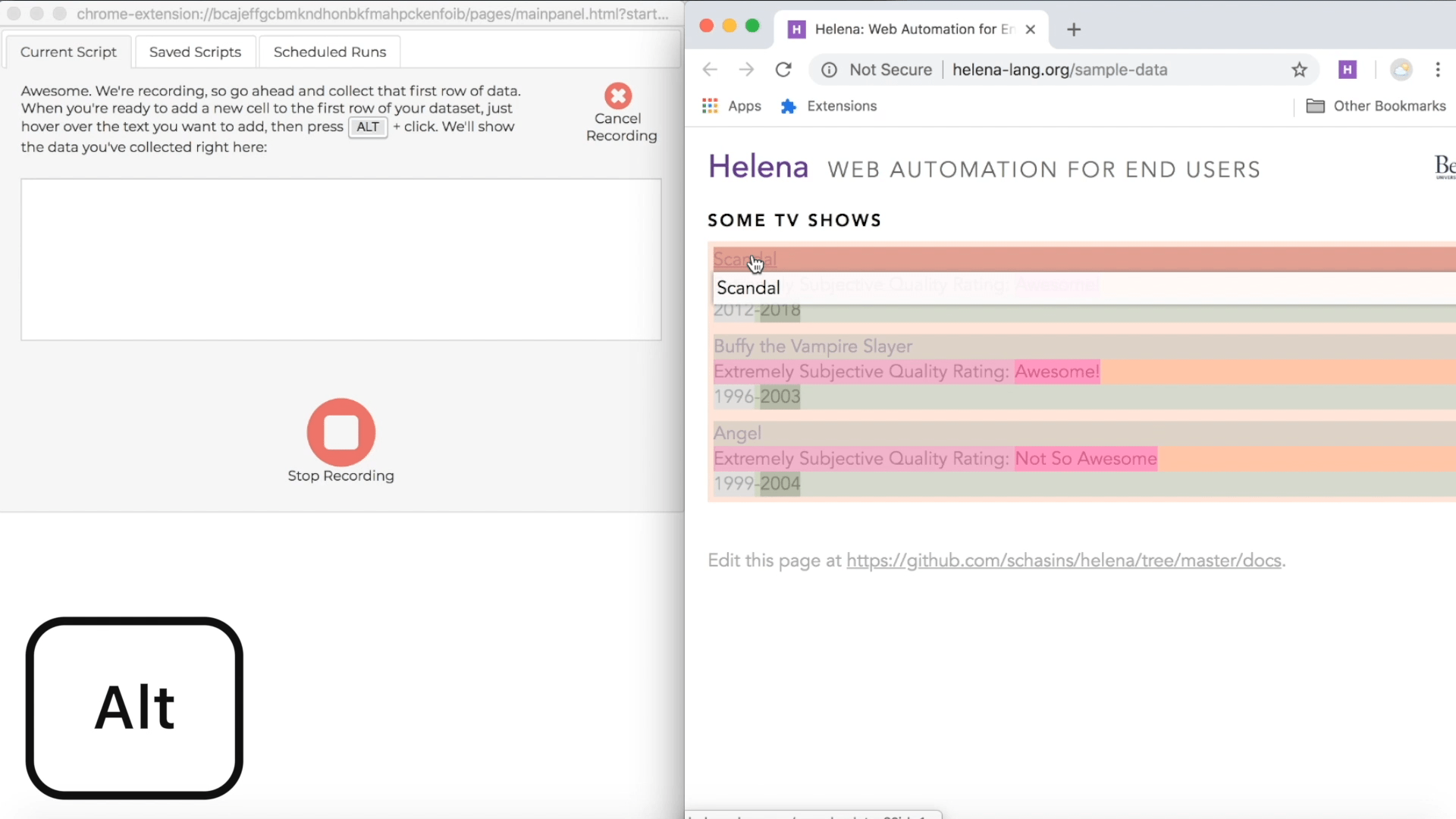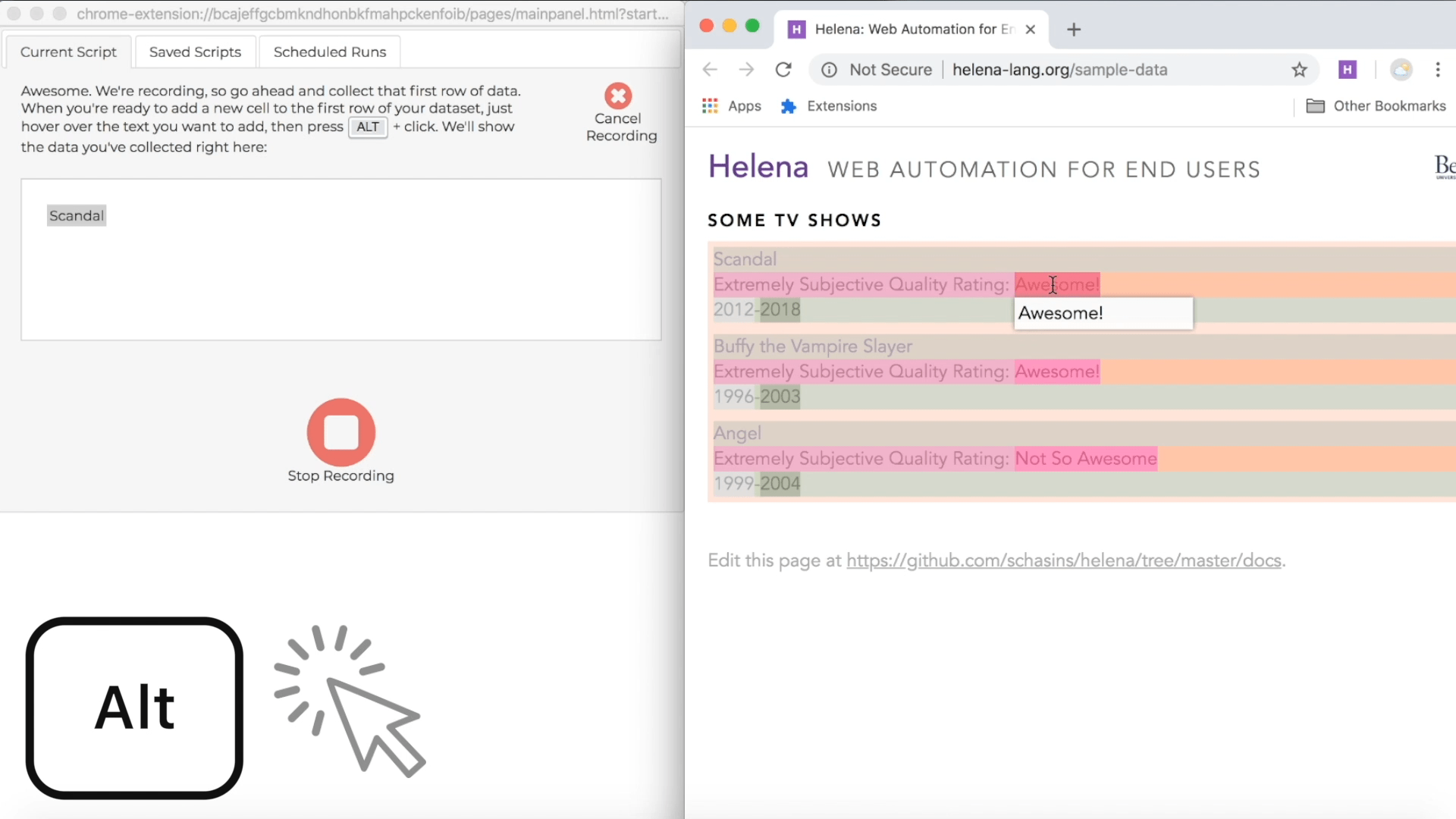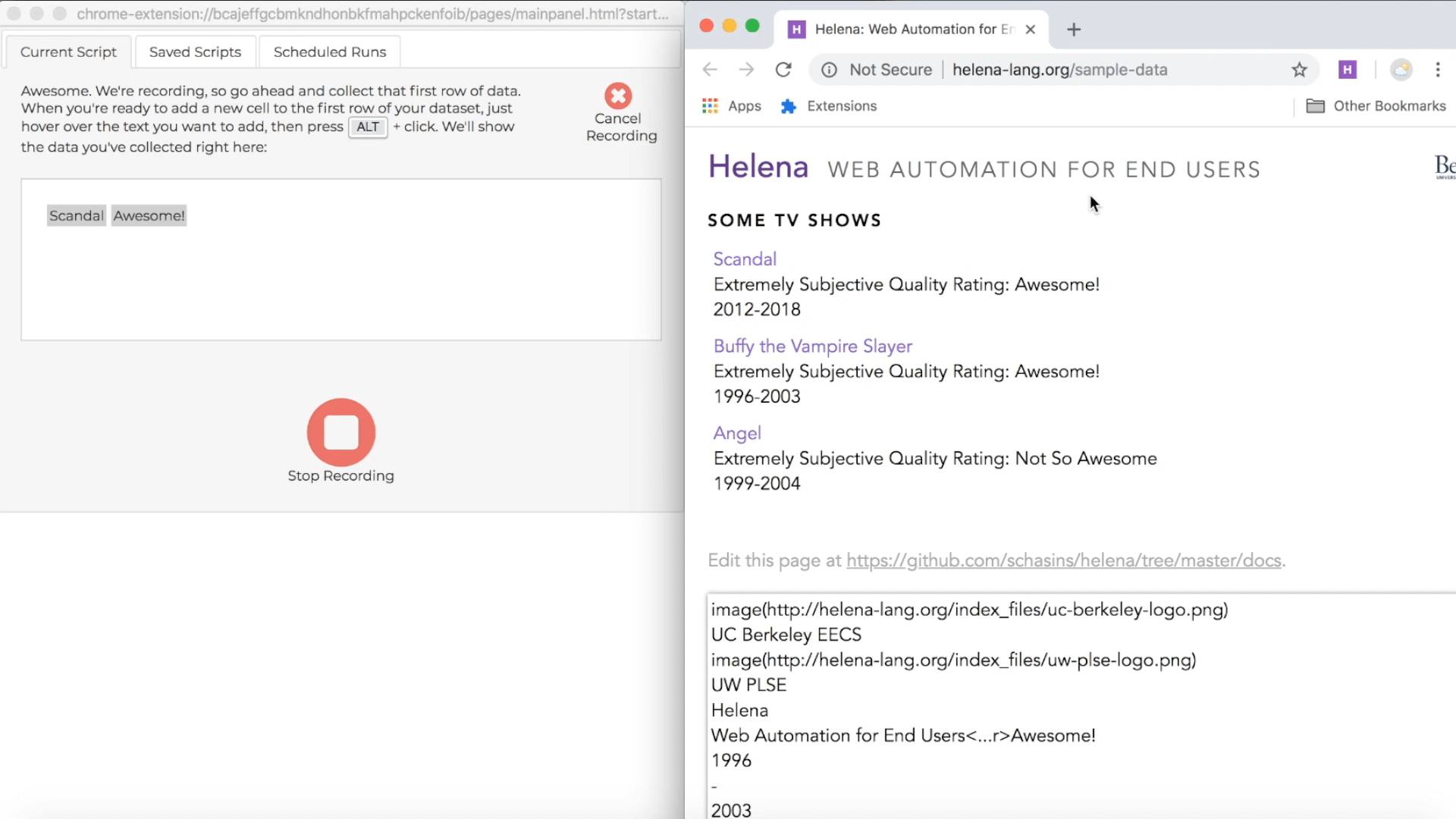
first row of the dataset you want. We already decided that our first row is the title and subjective rating of the first show in our list, so "Scandal" and "Awesome!" from
http://helena-lang.org/sample-data. Let's figure out if we can scrape that. When you're doing a Helena demonstration, you can interact with the browser as usual, but you'll see a couple new things too. First, you can get hints about what kind of data Helena can collect for you. As you mouse over the page, you'll see a little white box following your mouse. That box shows the text Helena can collect from the element currently under your mouse.
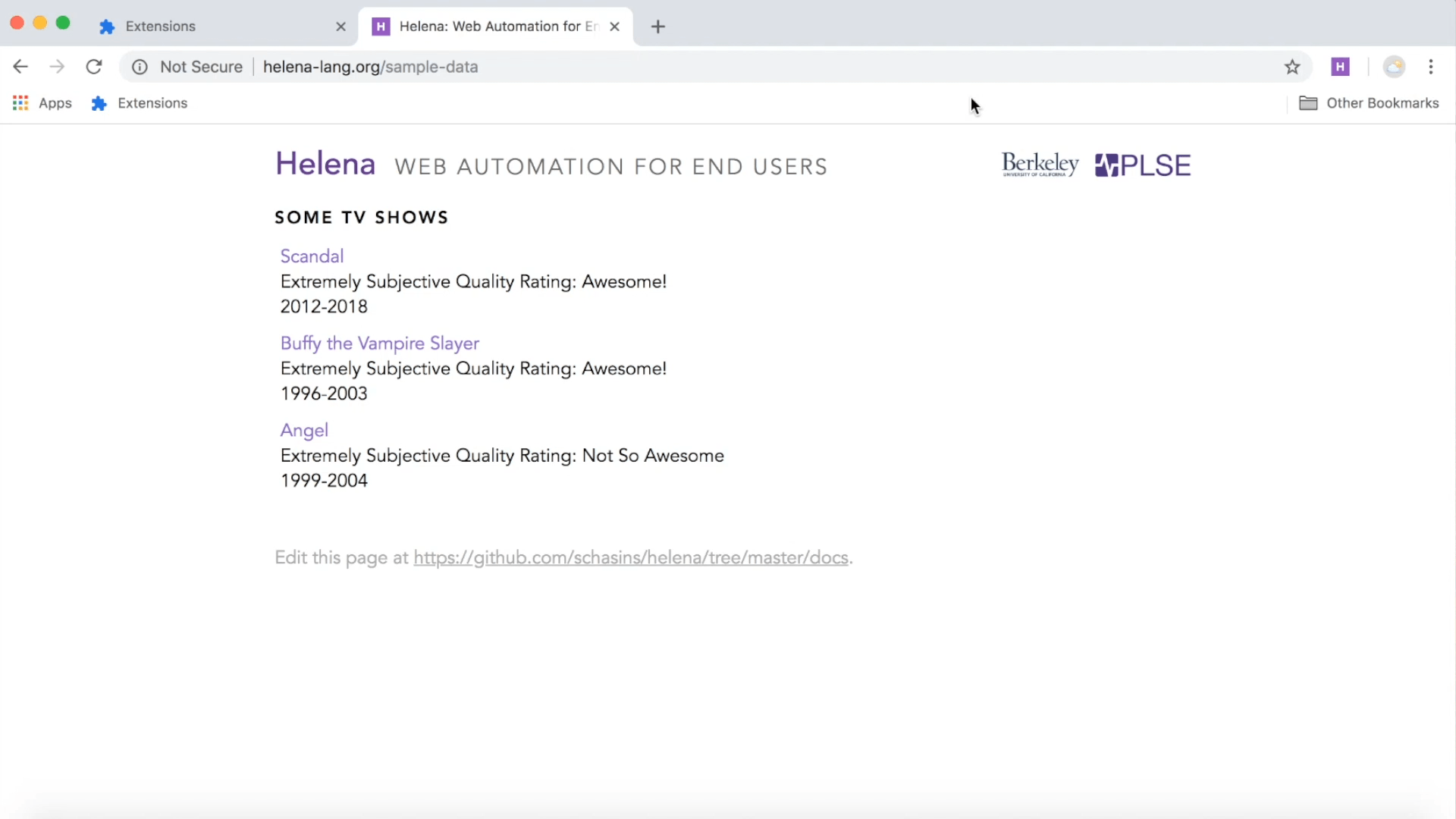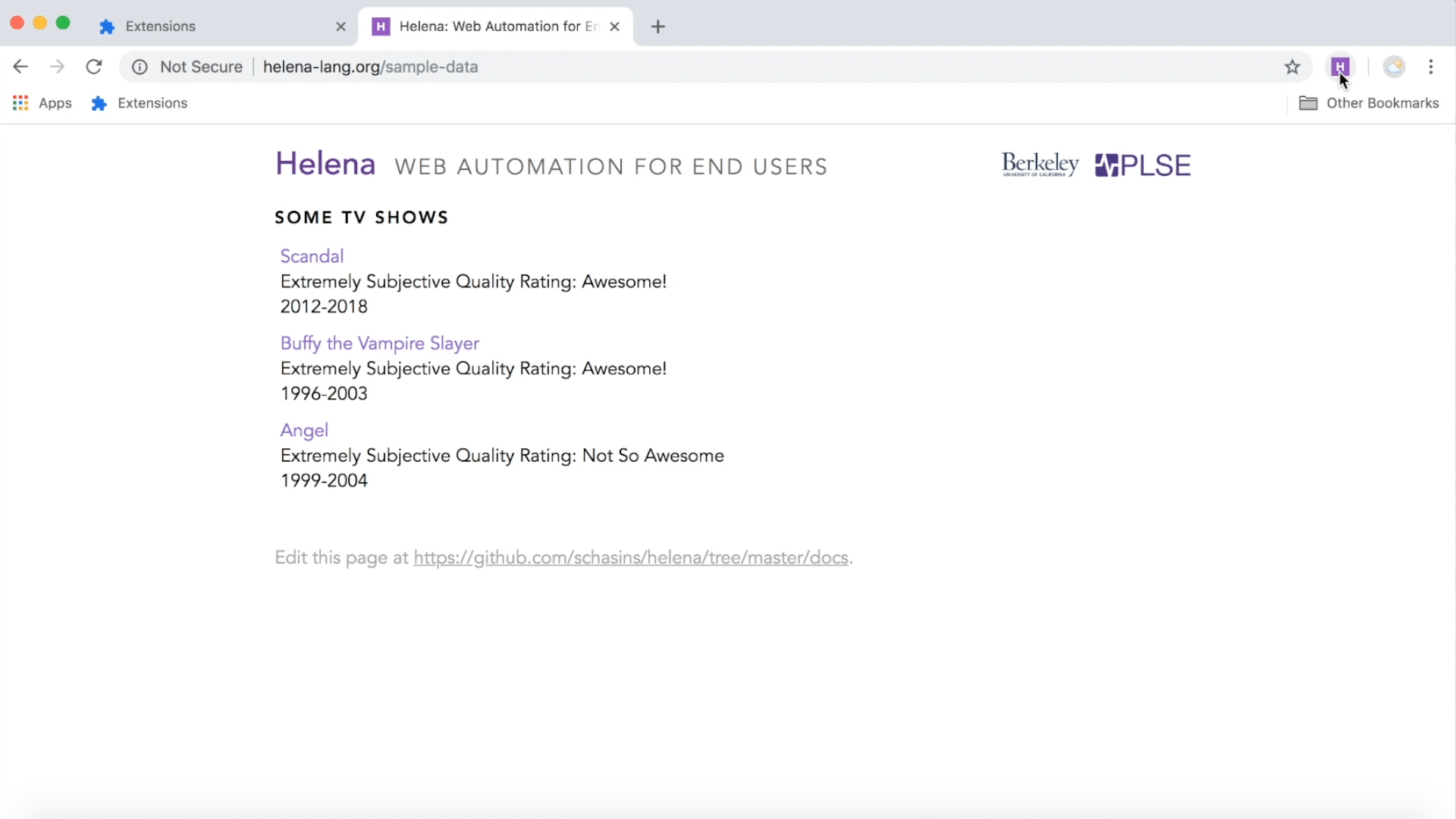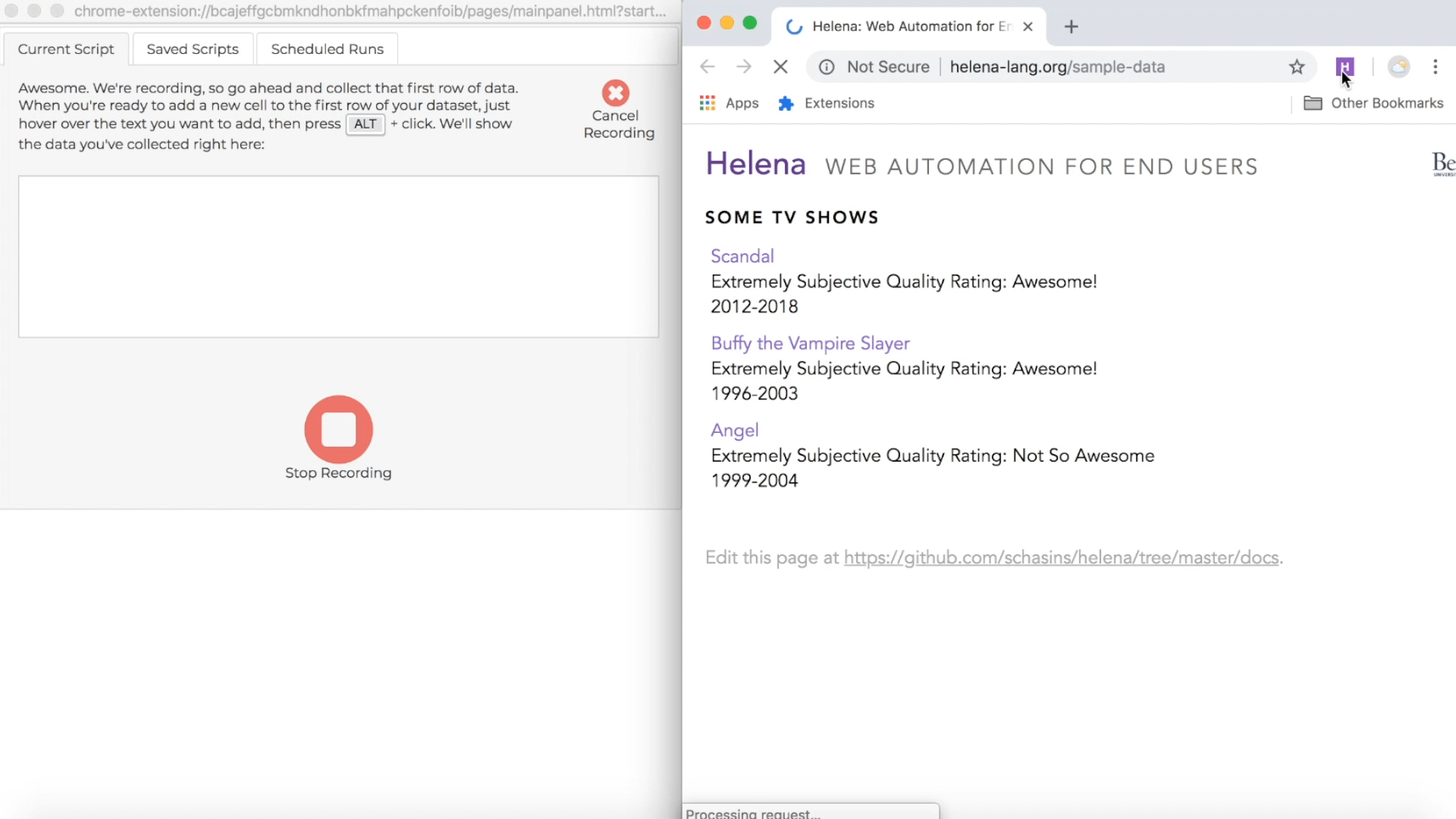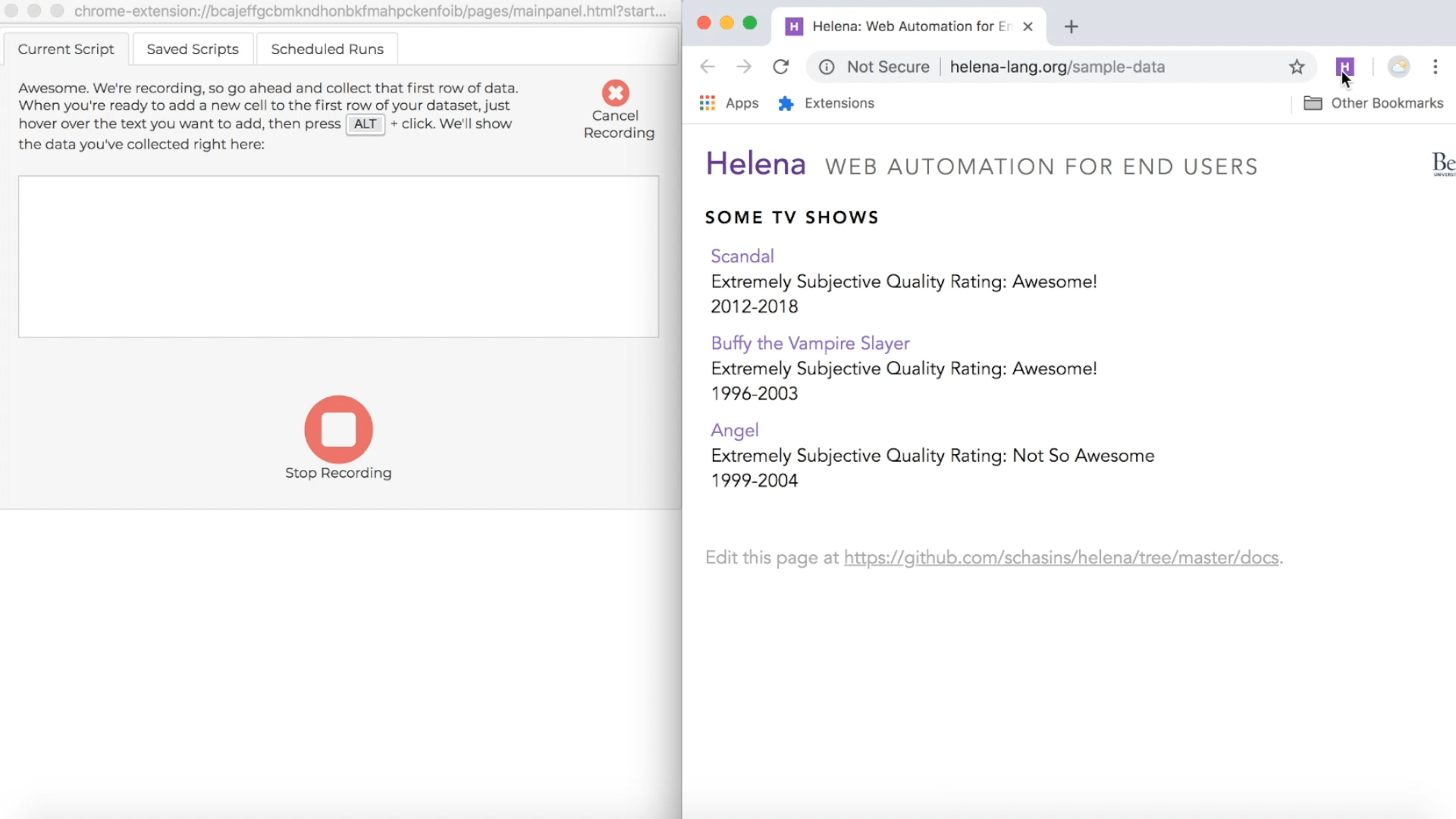
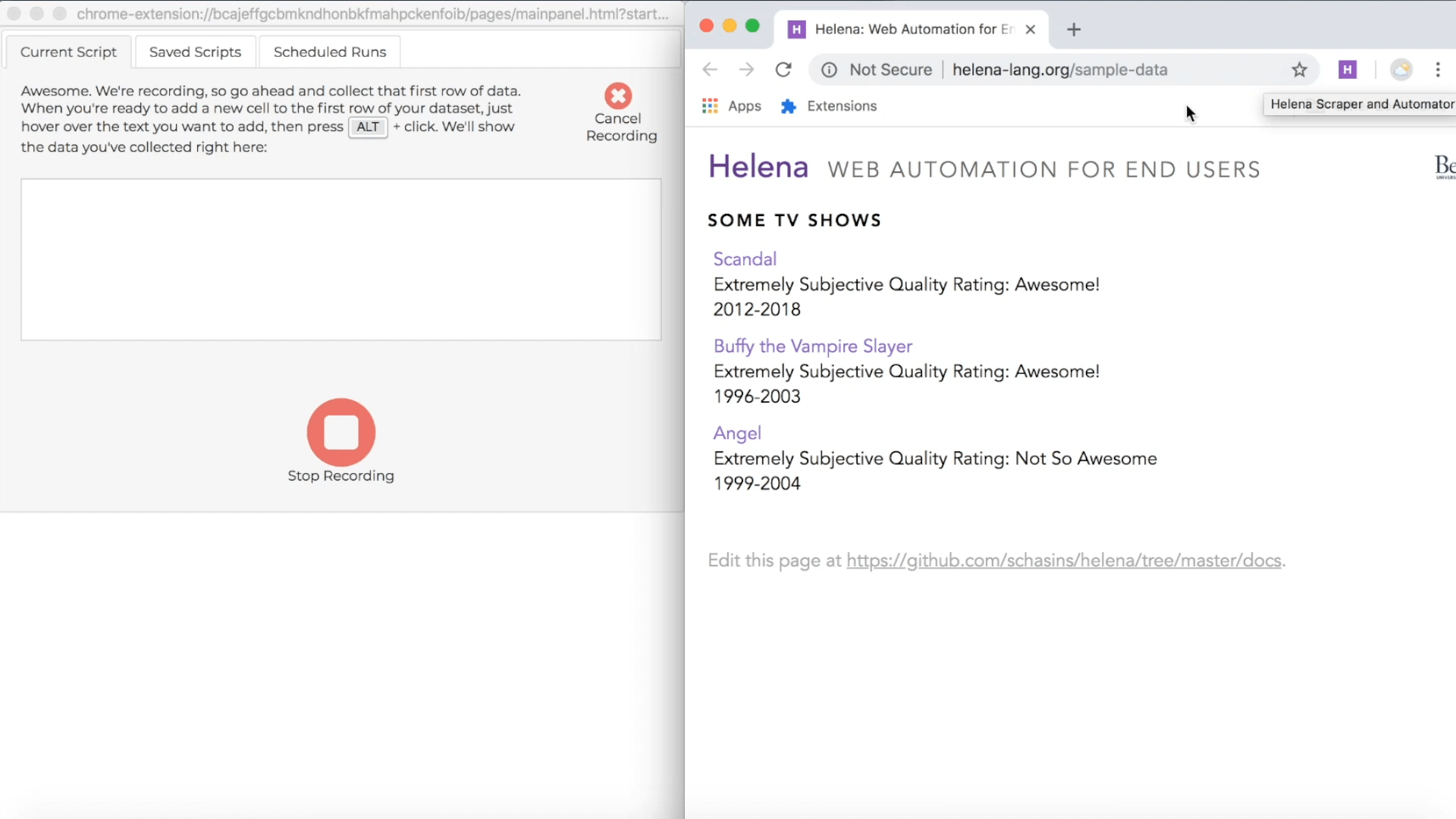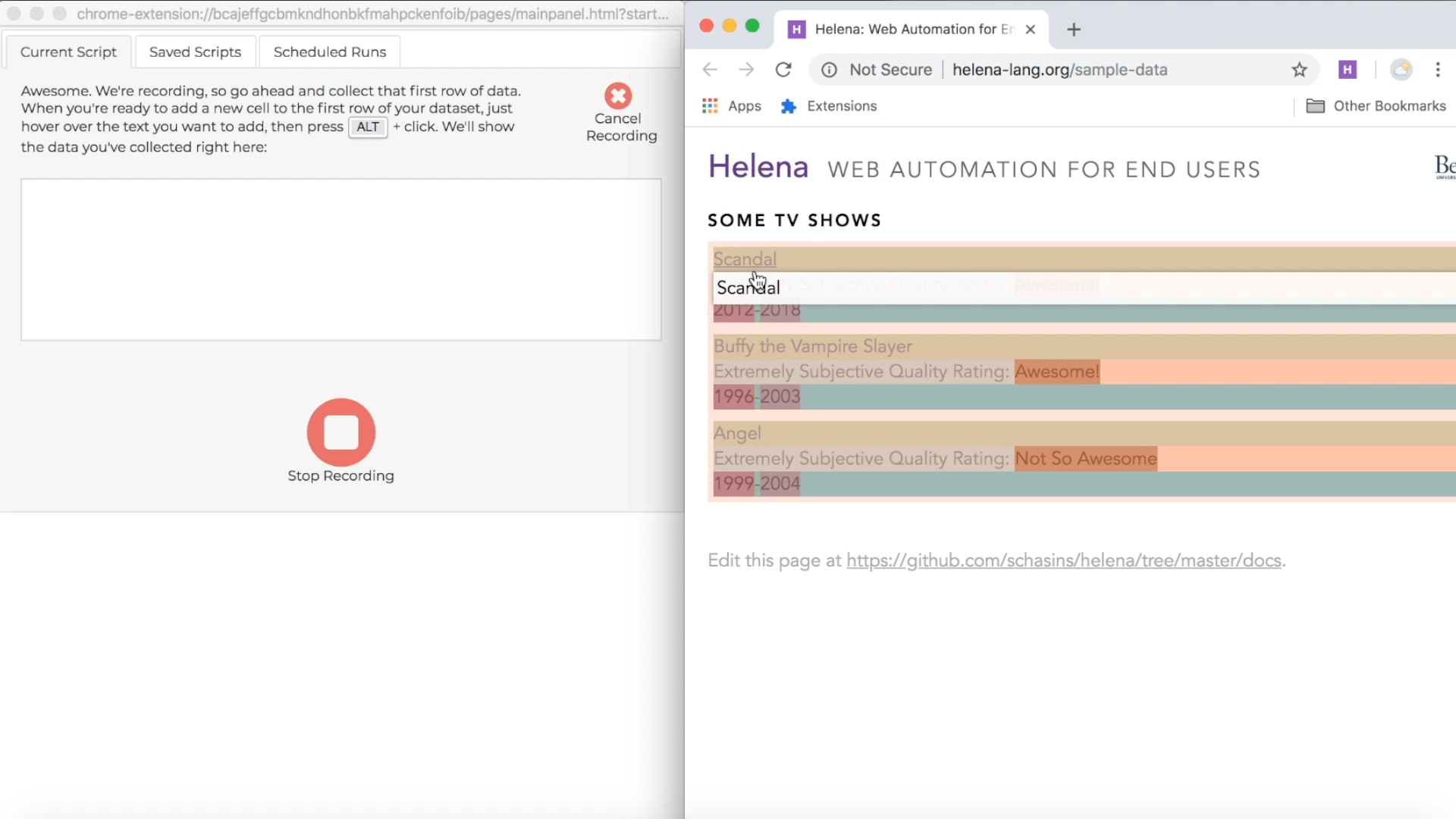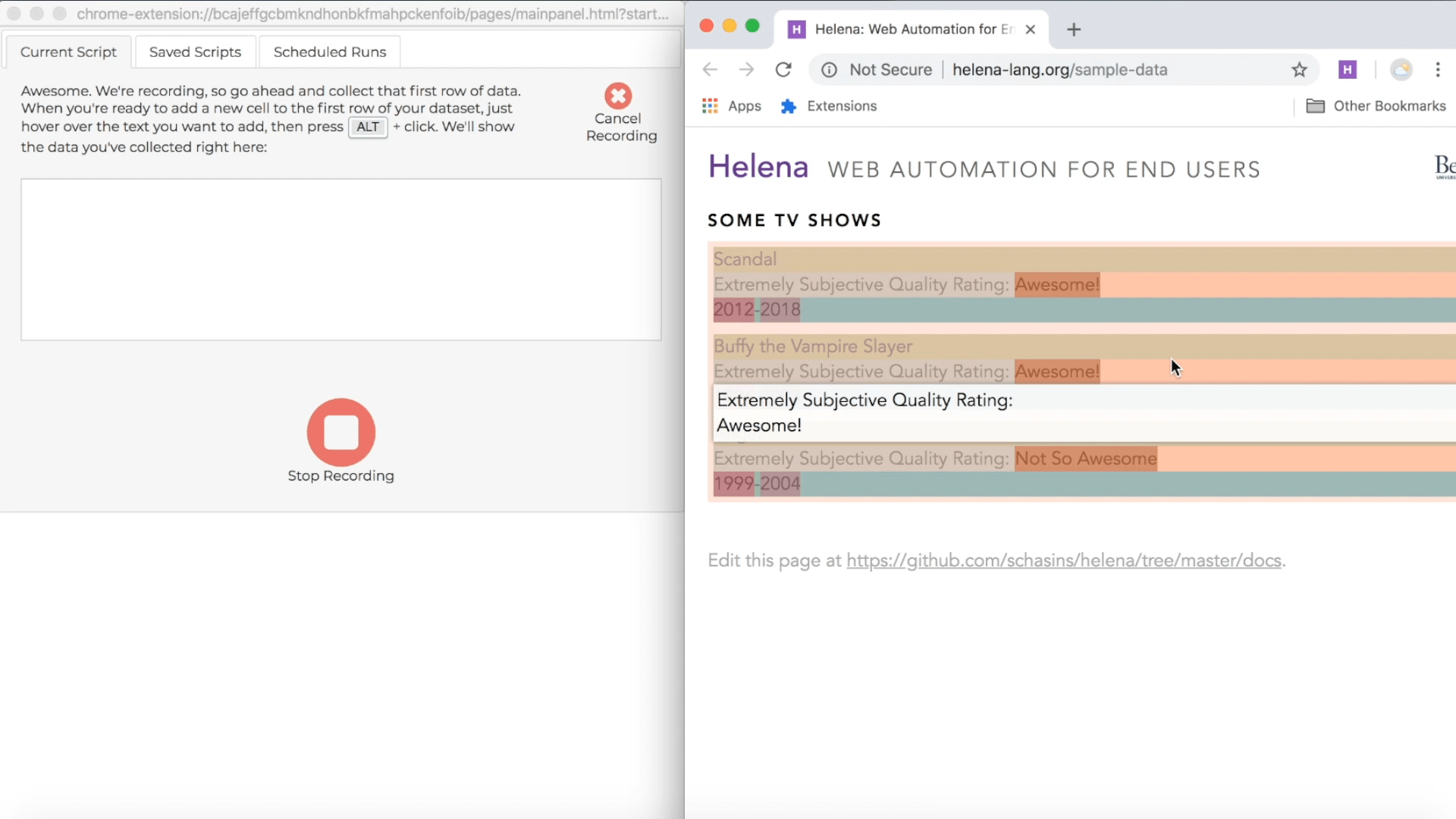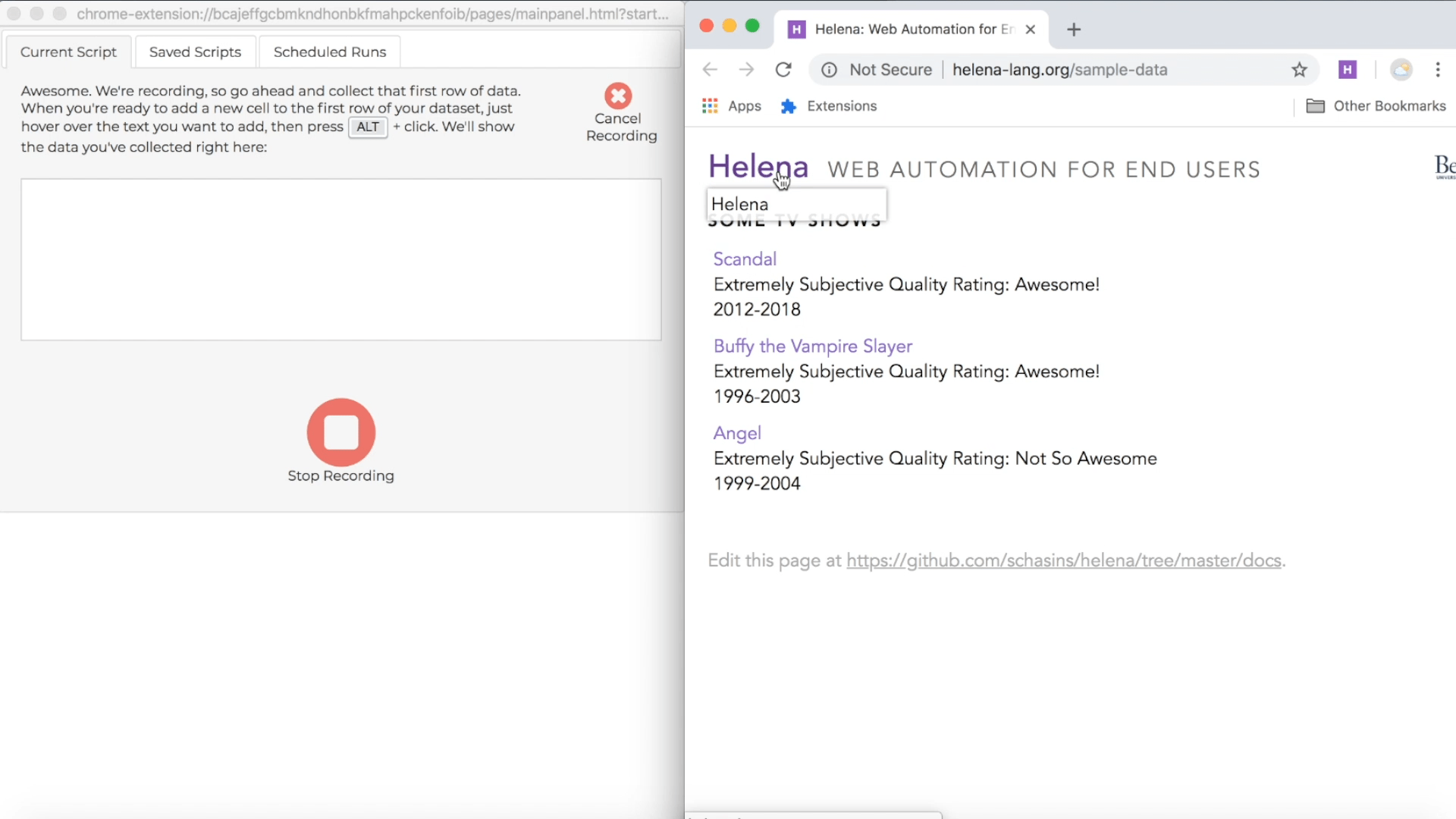
Collect some cells
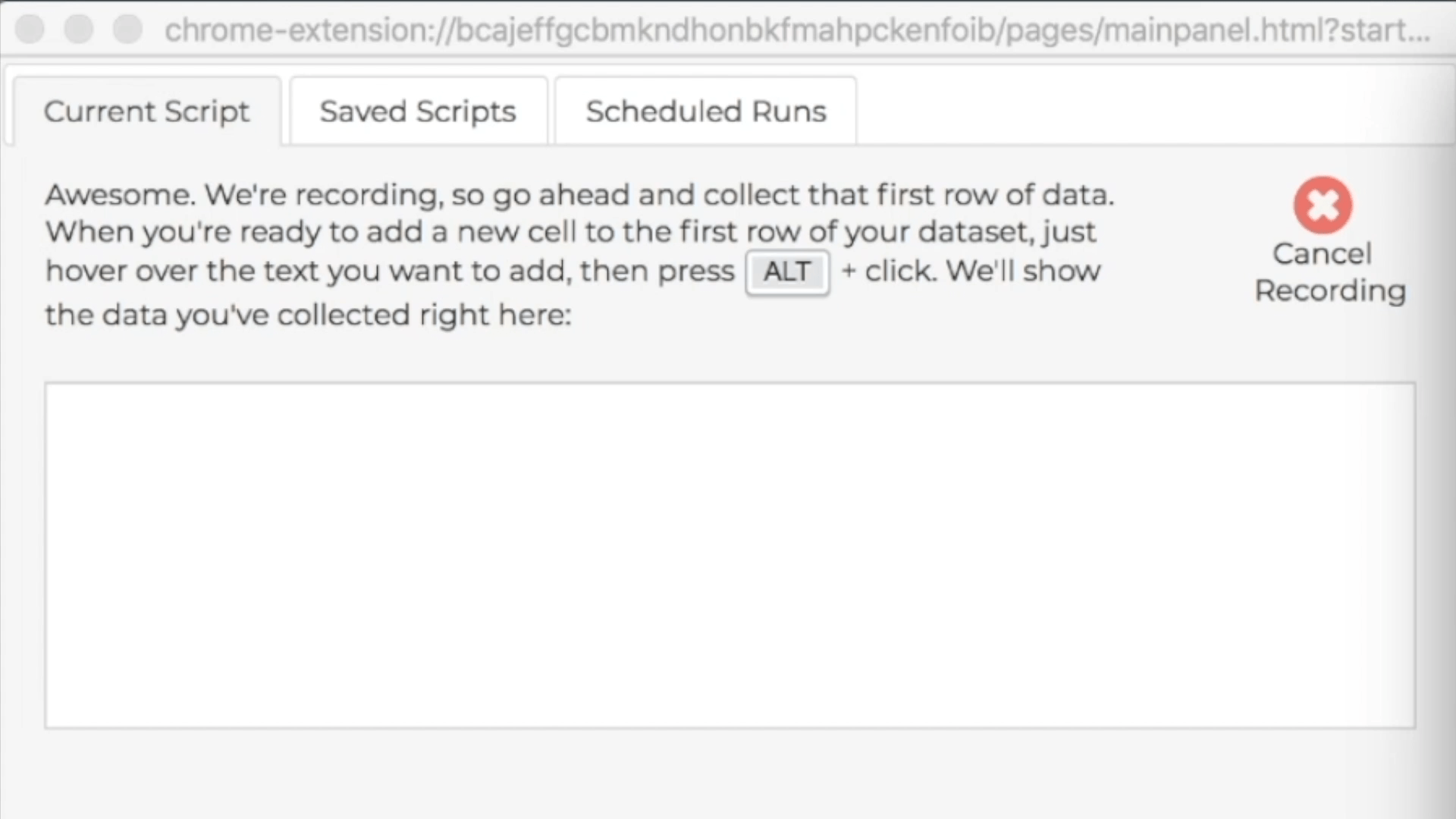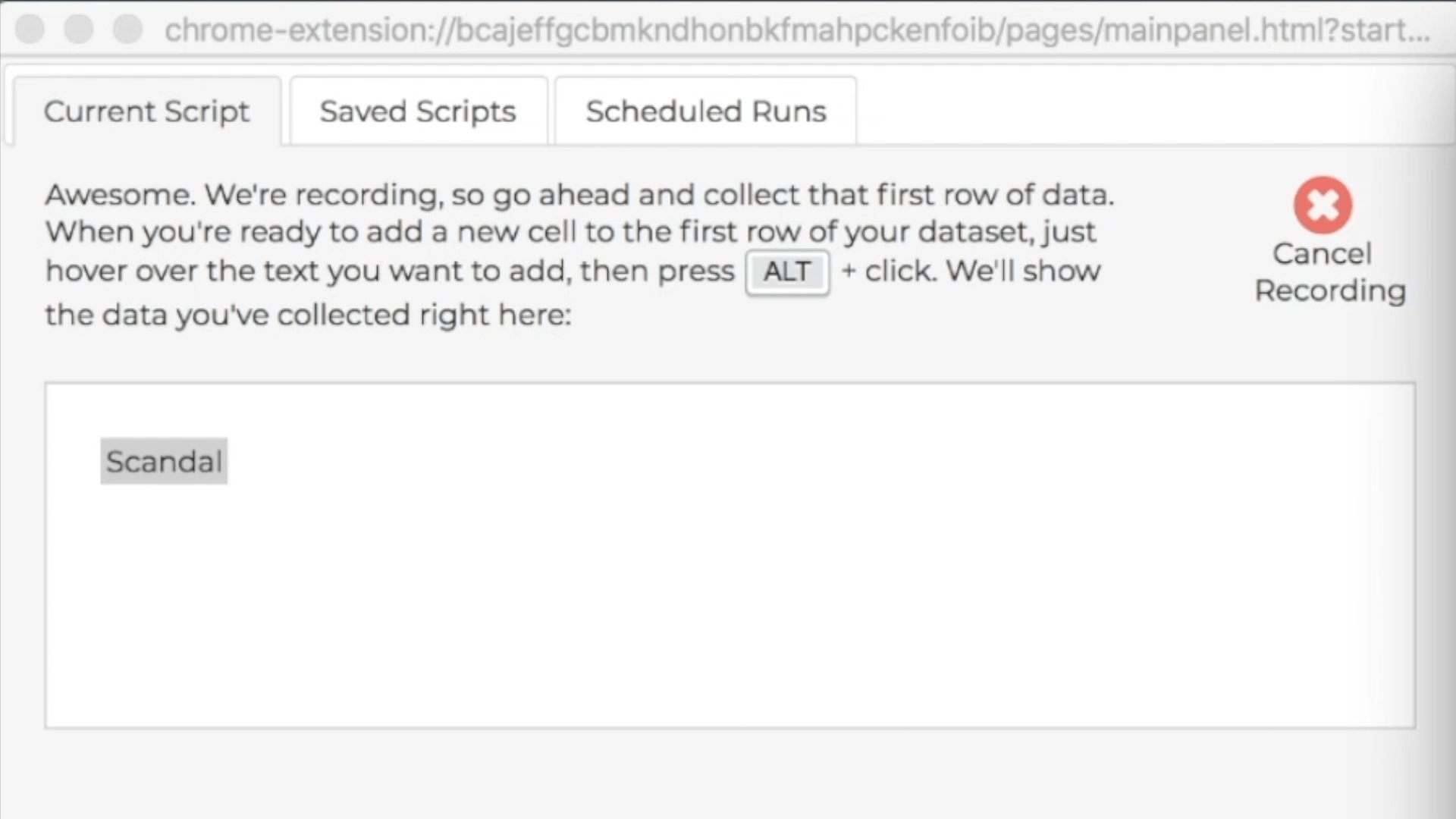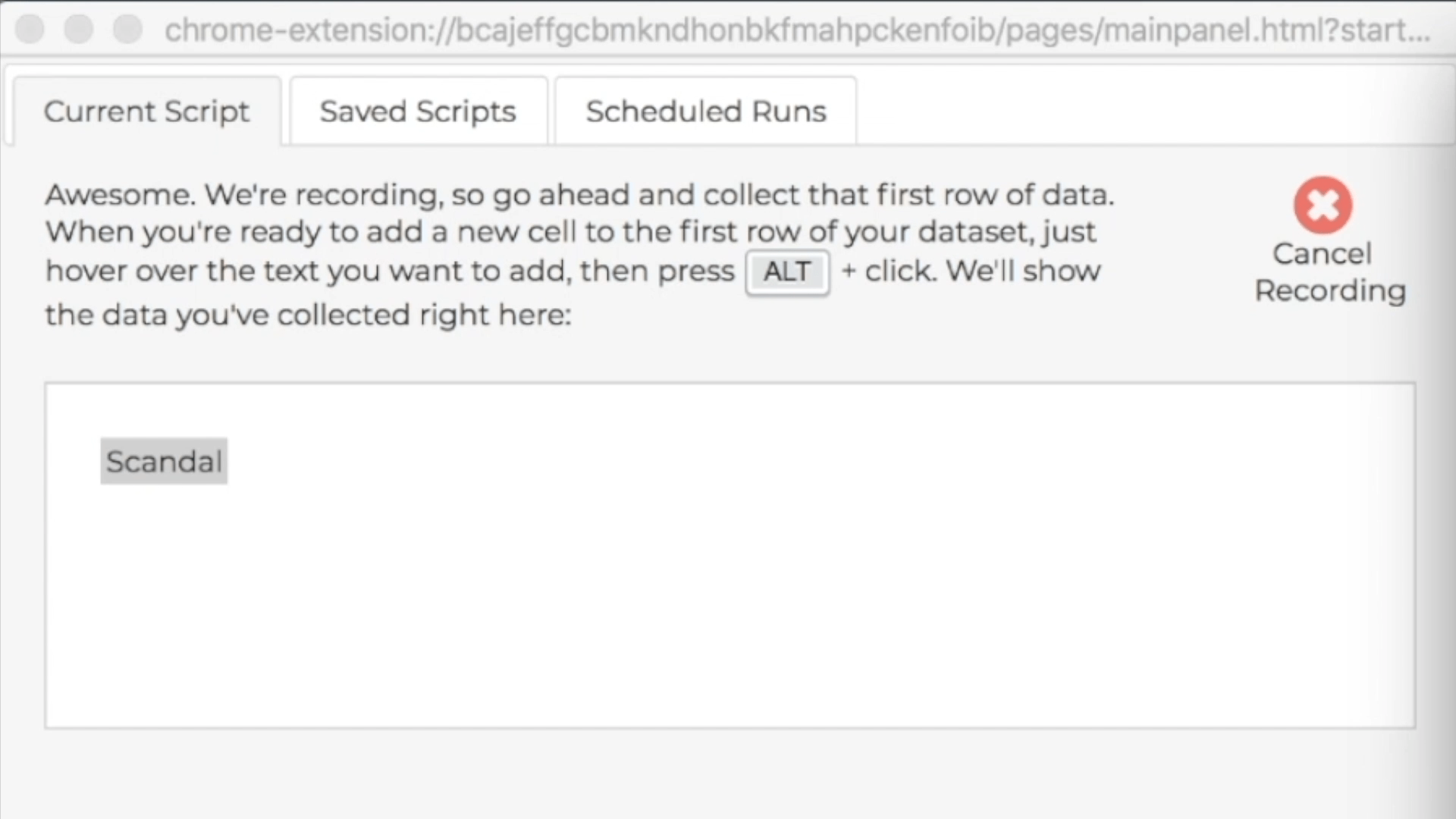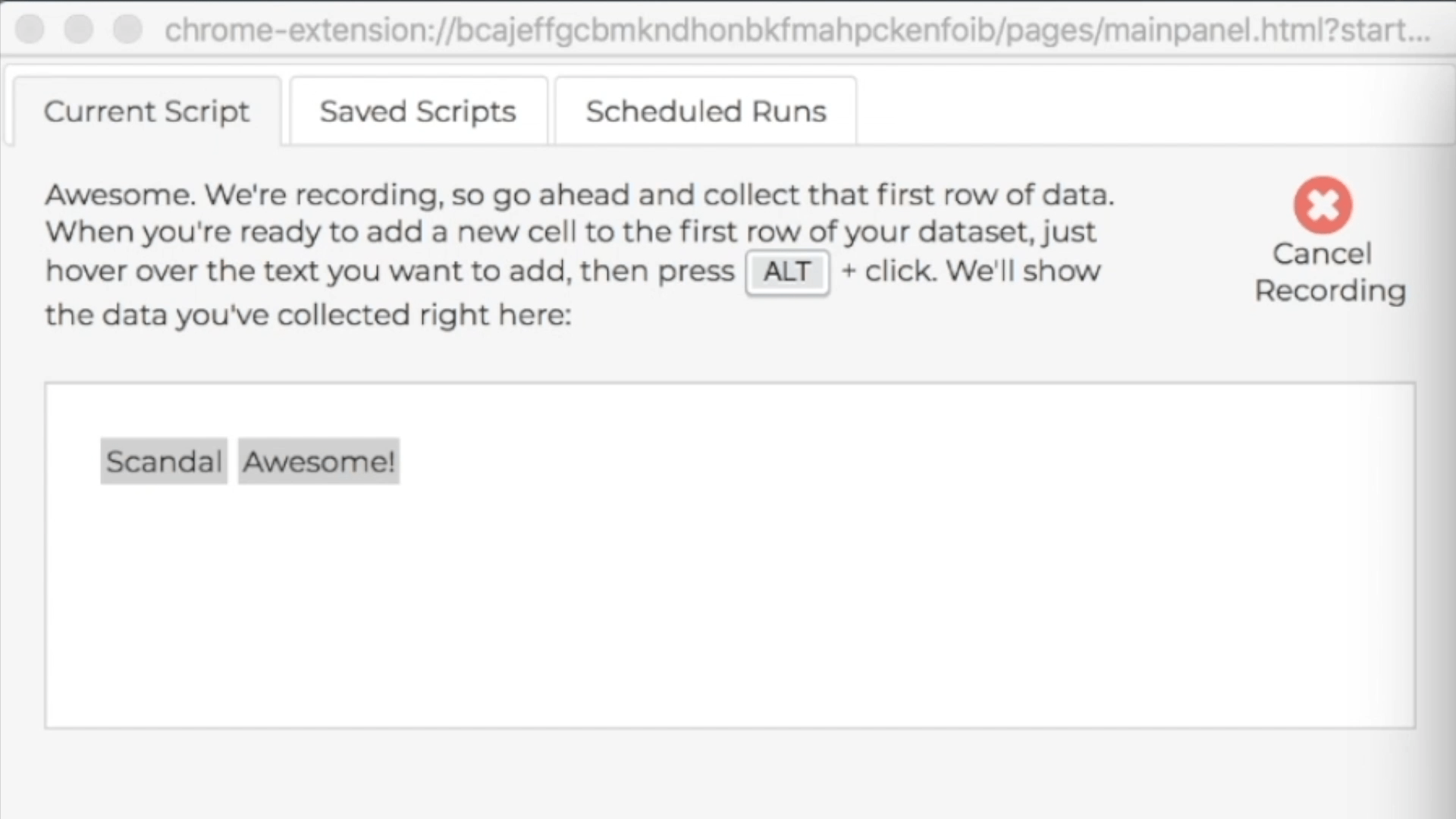
During a recording, the control pane shows directions for how to collect data from webpages, and the directions include a keyboard shortcut you can use. The particular shortcut varies based on what operating system you're using, but usually it's just the ALT key, so we'll just talk about using the ALT key, and you can look at the instructions if that isn't working for you. During a demonstration, when you hold down the ALT key, you'll see a red highlight following your mouse around when you mouse over webpages in the recording window; this red highlight lets you know which webpage elements you can add as news cells to your first row of data. When you're ready to add new cells to the first row of your target dataset, hold down the ALT key, click on all the elements you want to add to the first row, then let up the ALT key. Remember, our first row is "Scandal" and "Awesome!", so we'll collect those cells right now:
In the control pane, you'll see the first row growing as you add new cells:
Collect link cells
The normal keyboard shortcut collects the text of a webpage element, but if the webpage element is a link, you can also collect the URL/href associated with the link. Just hold down the normal keyboard shortcut plus the SHIFT key, then click. The preview pane at left will show the URL - if the element has one!
Stop recording
Once you've collected all the data you want in your first row, click on the 'Stop Recording' button. Helena will analyze the webpages you used to figure out if there are any relevant tables. For instance, we interacted with the first TV show in a table of TV shows, so it will guess that we want to collect information about all TV shows in the list. You can sit back and wait while the tool figures out what tables to use. Here's how this process looks in the tool:
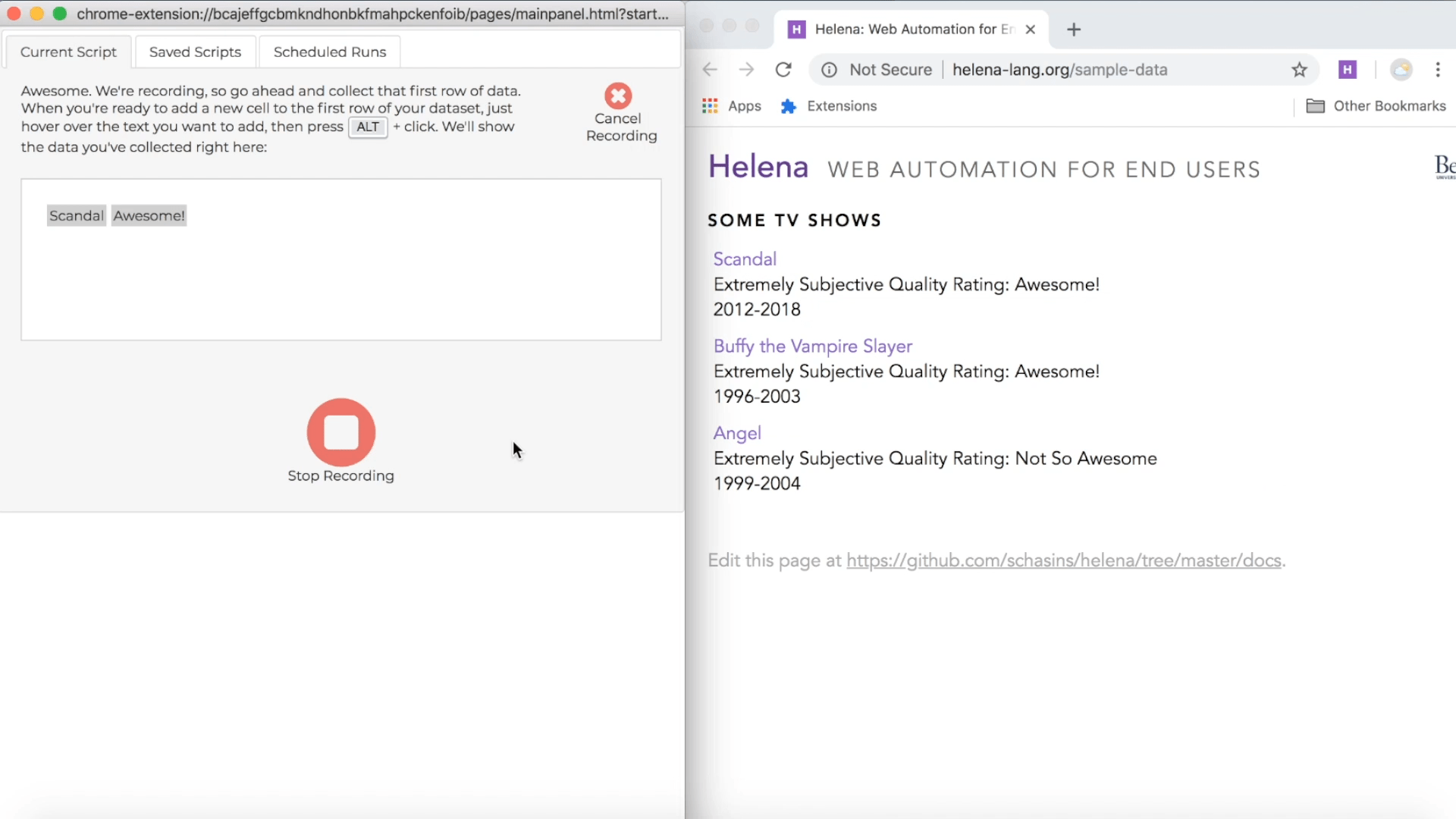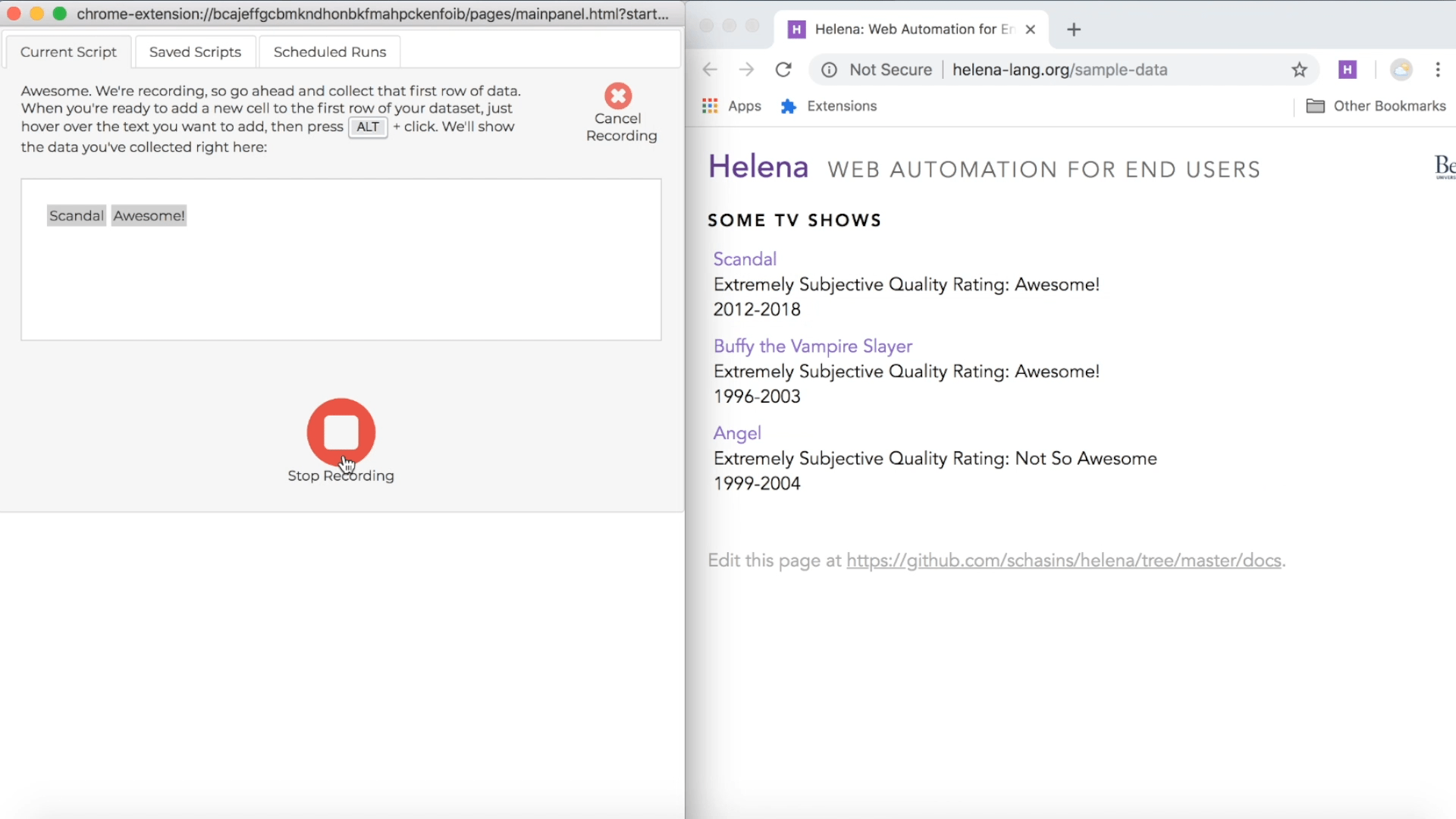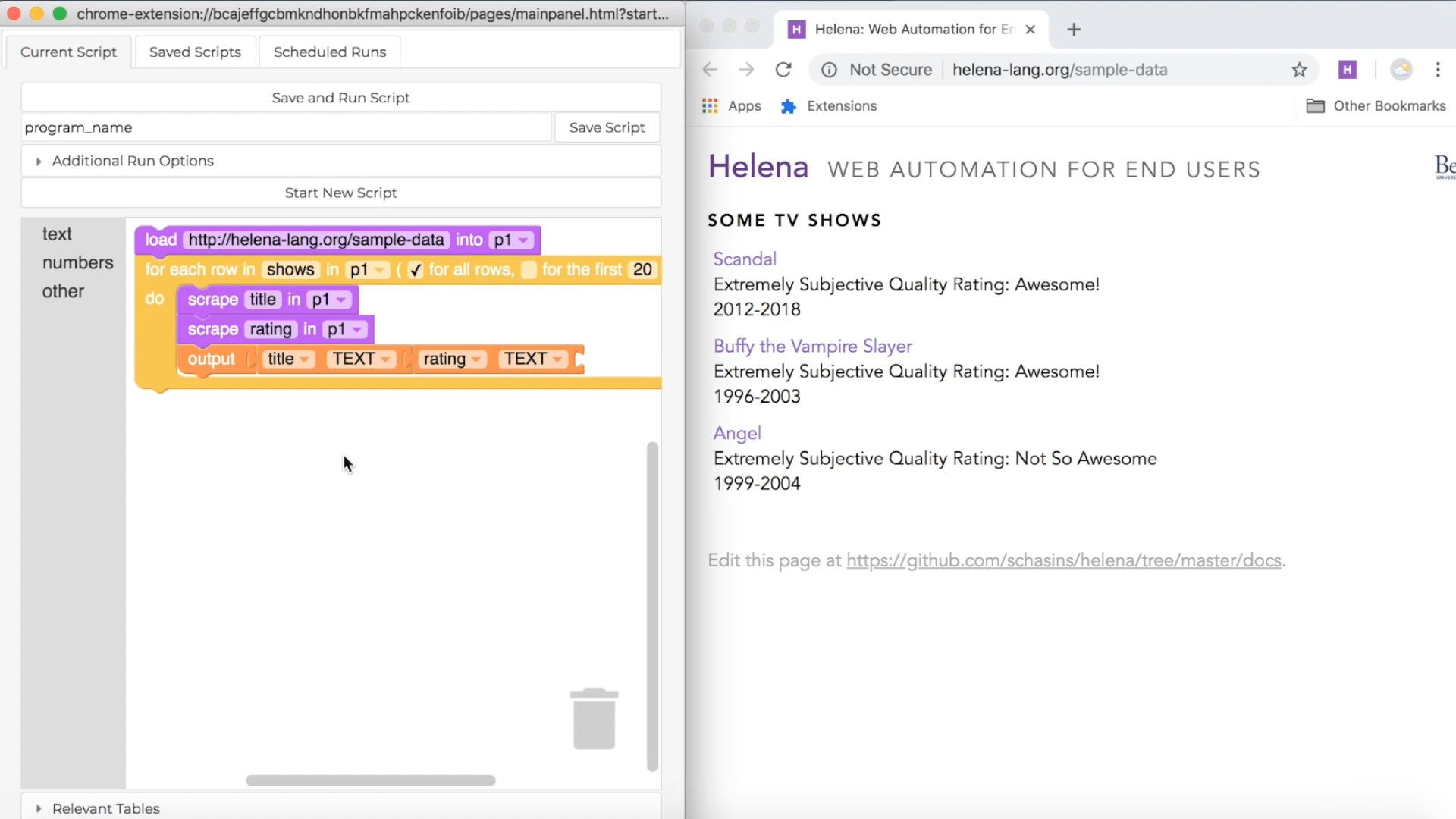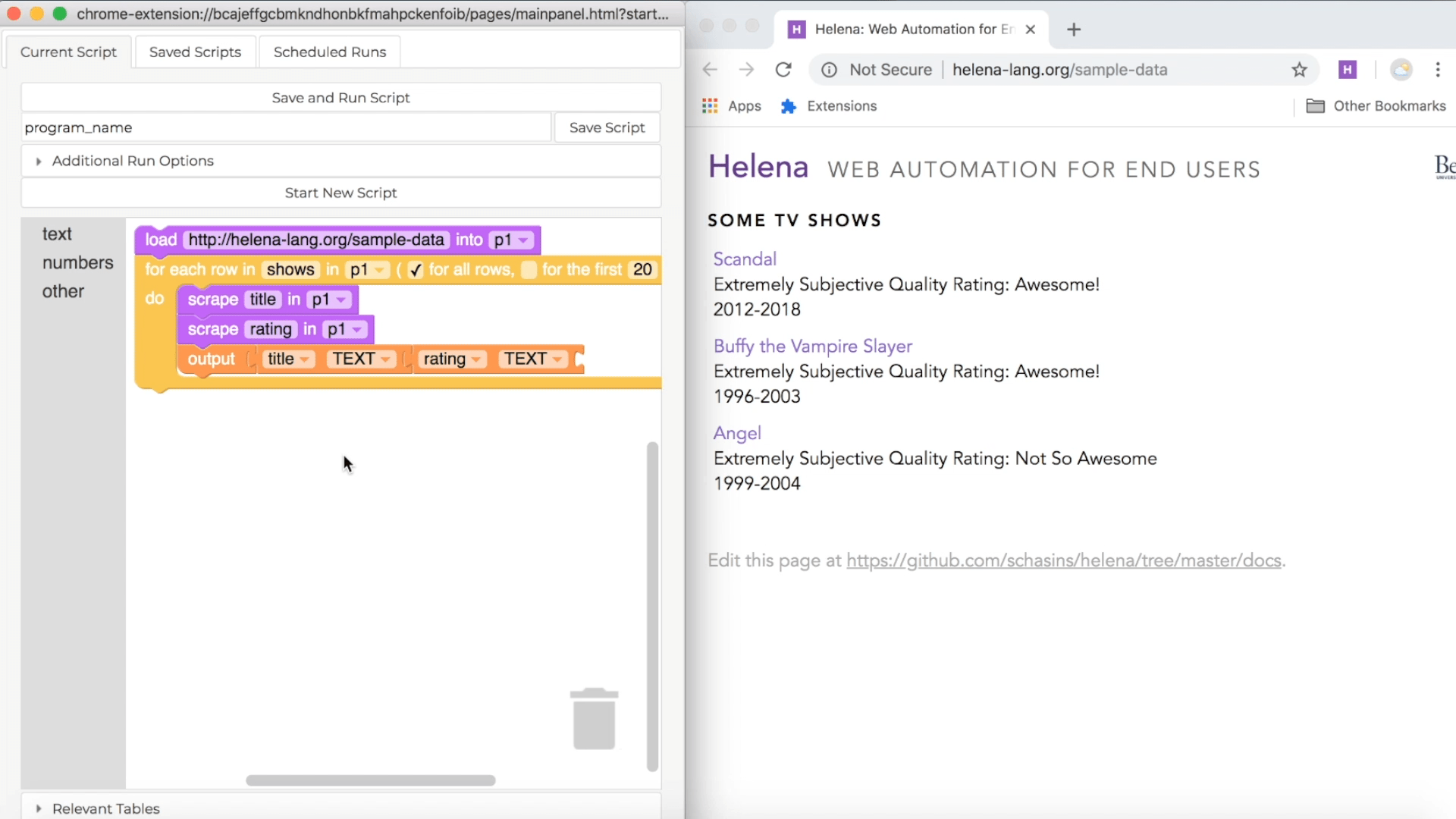
In the control pane on the left, we see a representation of the program Helena has written. The purple blocks represent actions you took during your recording. The orange block adds a row of data to your output dataset. The yellow block is a loop, and it represents repeating actions for each row in a table. For instance, here the yellow block will cause us to repeat actions for each TV show in a table of TV shows. Helena may or may not have good names for the tables you use, depending on whether other Helena users have used the tables before. In this case, someone has used the TV shows table before and given it a descriptive name, so we see a nice name in our program.
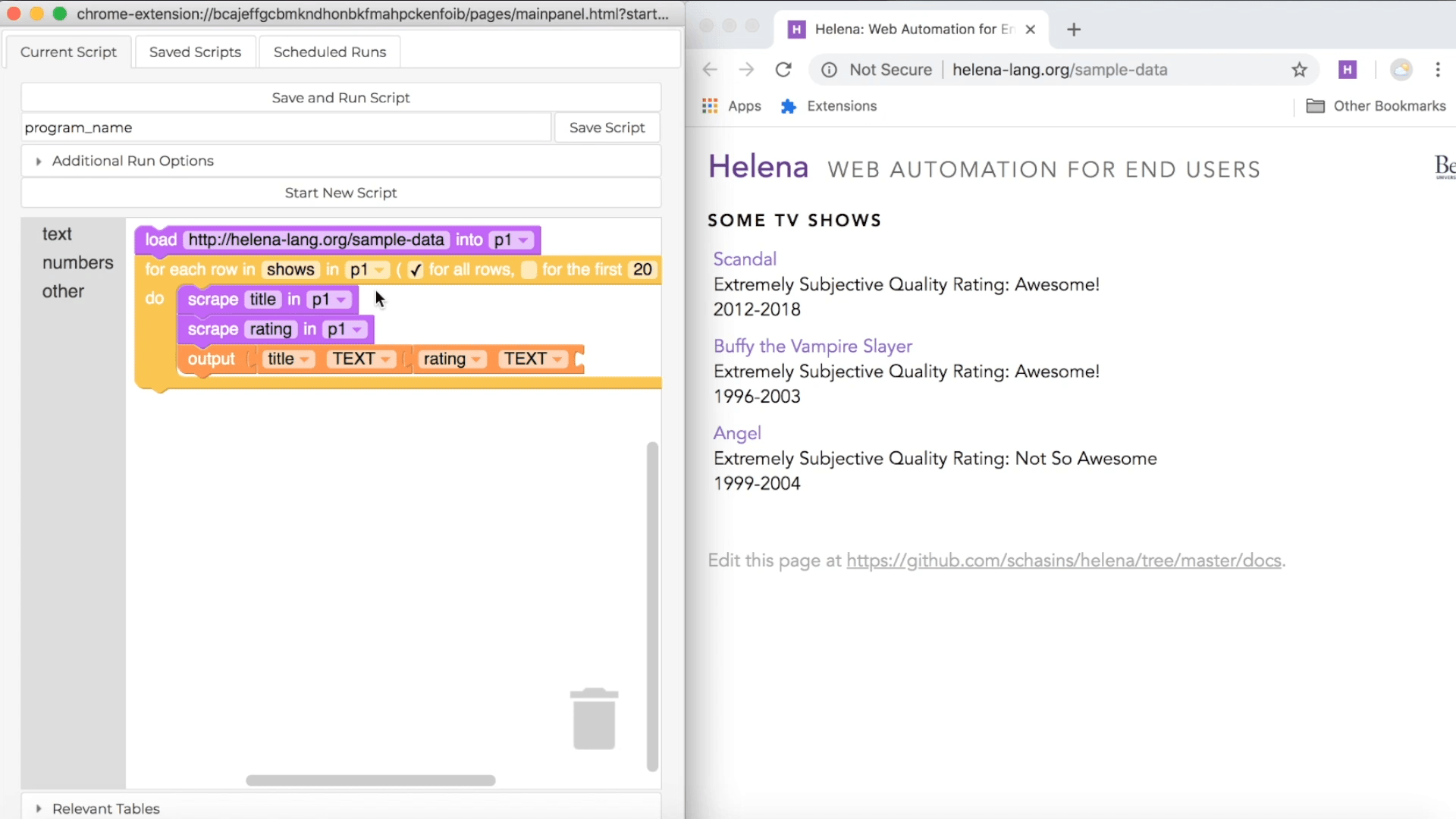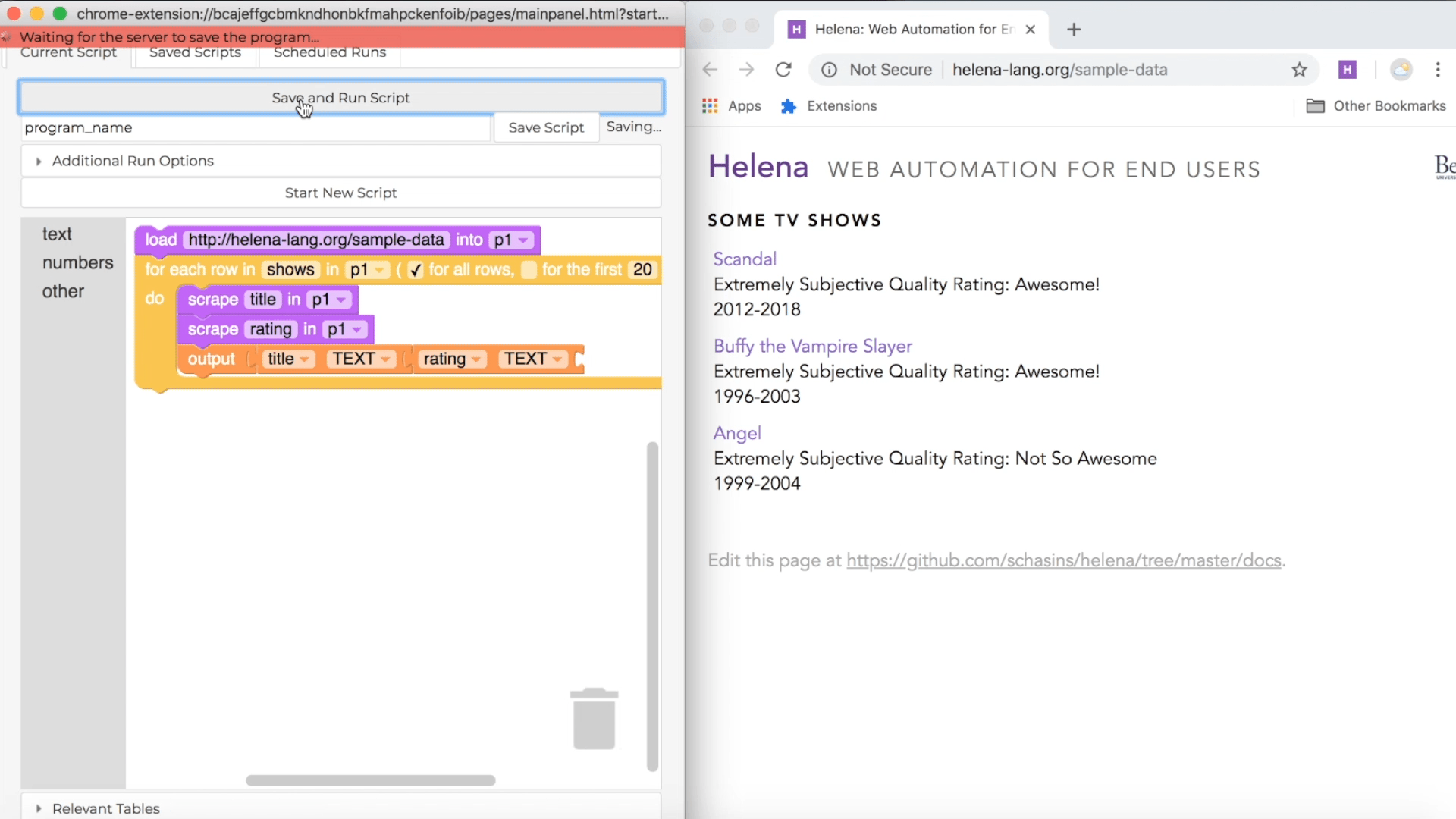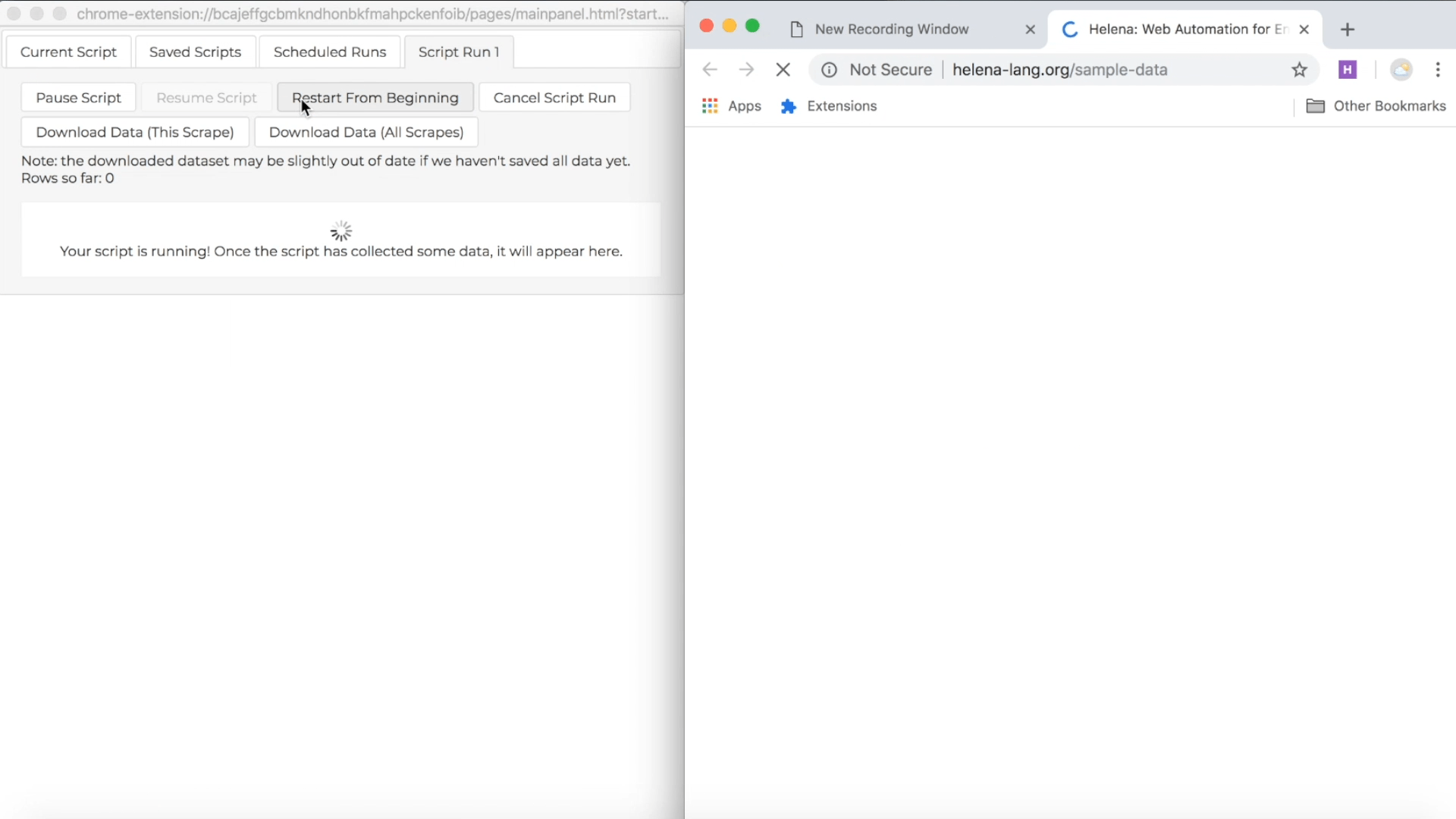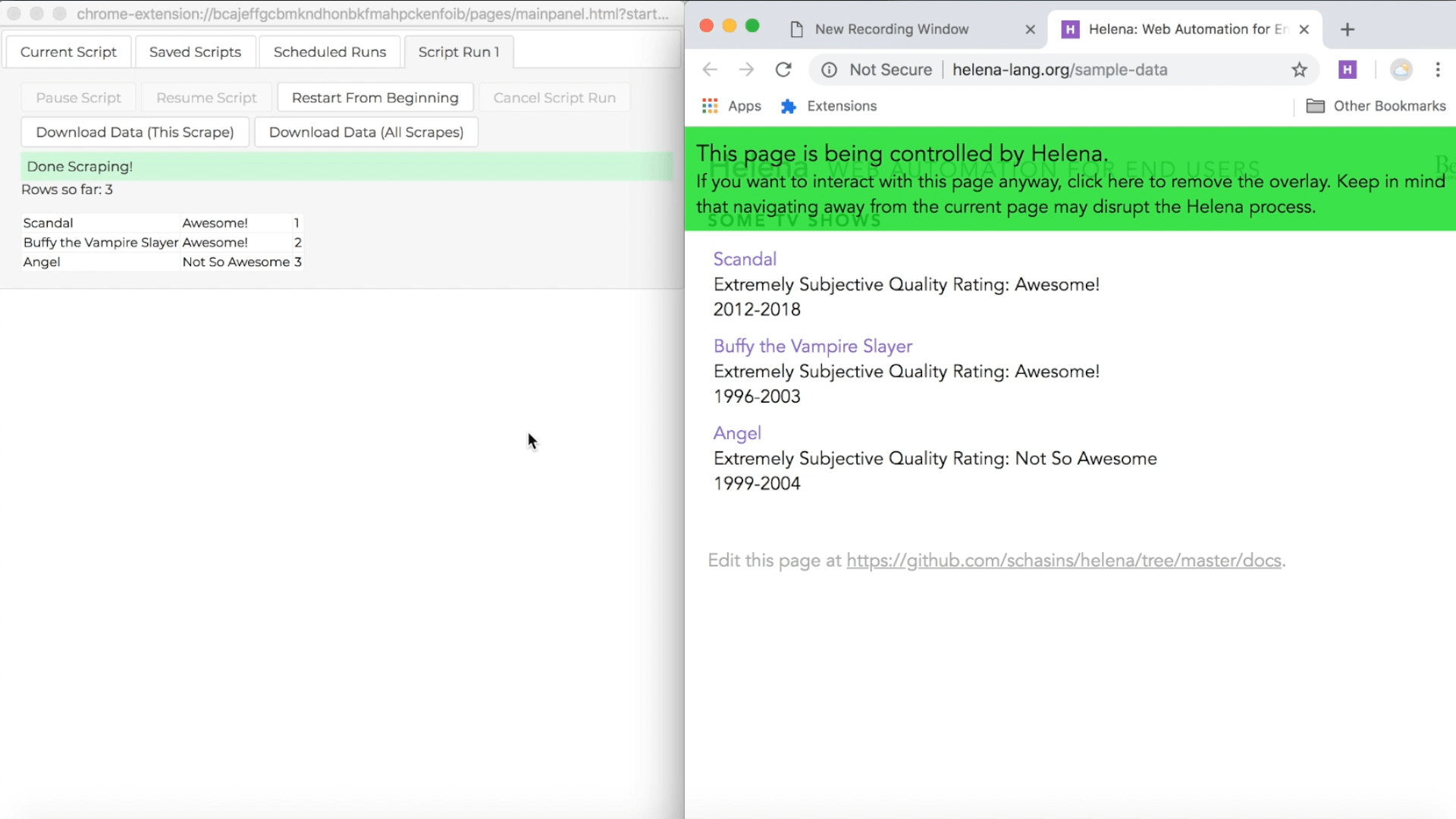
Run a program
Now that Helena has written the program, let's run it. Just click the run button in the control pane. The control pane will show a preview of the dataset it's collecting. On the right you'll see the window Helena is using to access and collect all the data in the dataset.
Exercise 1: If you haven't been trying this process yourself so far, now's a great time to see if you can get this program up and running yourself.
Exercise 2: Try collecting this dataset instead:
| Scandal |
2012 |
2018 |
| Buffy the Vampire Slayer |
1996 |
2003 |
| Angel |
1999 |
2004 |
Use multiple tables
Let's get a little fancier. Say we want to collect multiple tables - say, information about each TV show and for each TV show, information about each character:
| Scandal |
Olivia Pope |
| Scandal |
Abby Whelan |
| Buffy the Vampire Slayer |
Buffy Summers |
| ... |
... |
We'll need to interact with the TV shows table but also a bunch of character tables. To collect this data, we'll do the same thing we did before - demonstrating how to collect the first row - but this time the first row will come from multiple webpages:
Notice the green highlights that Helena uses to indicate it's interacting with particular webpage elements. Remember, everything you do during a recording is also going to be done by your program, so keep your recording streamlined if you want to keep your program streamlined.
Exercise 3: Collect this dataset of TV shows and characters.
Download data
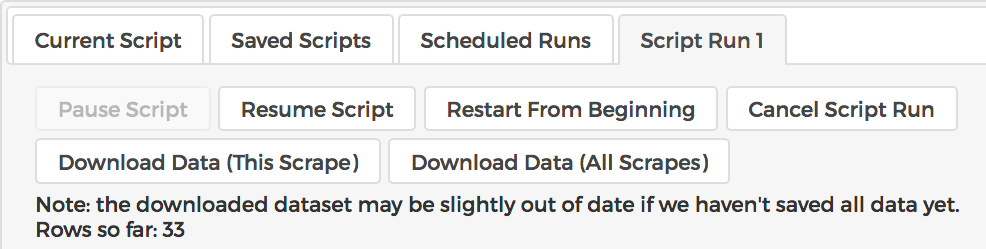
Once you've collected a dataset, you can use the download buttons to download the datset spreadsheets (in CSV format).
The button on the left, "Download Data (This Scrape)" downloads a CSV that includes all the data collected by the current program run - the rows in the current "Script Run" tab in the control pane. The button on the right, "Download Data (All Scrapes)" downloads a CSV that includes all the data ever collected by any run of the program.
Try a real website
Let's try a real website. Play around with the data available at Google Scholar, specifically at this webpage:
https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label%3Acomputer_science. Try to figure out how to collect this target dataset:
| Geoffrey Hinton |
Emeritus Prof. Comp Sci, U.Toronto & Engineering Fellow, Google |
| DEYWIS MORENO |
High Energy Physicist, Universidad Antonio Narino |
| ... |
... |
Did you figure it out? Here's how it goes:
Exercise 4: Collect this target dataset.
Try multiple tables from a real website
Let's scale up to a large dataset! We're going to start at
https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label%3Acomputer_science again. But this time our target dataset is this:
| Geoffrey Hinton |
Learning internal representations by error-propagation |
1986 |
| Geoffrey Hinton |
Learning representations by back-propagating errors |
1986 |
| ... |
... |
... |
| DEYWIS MORENO |
The ATLAS experiment at the CERN large hadron collider |
2008 |
| ... |
... |
... |
Notice we don't just want papers from the first author - we want to go through all the papers by author 1, then all the papers by author 2, and so on. Here's how we collect it:
Exercise 5: Collect this target dataset.