The skip block is a special Helena block that makes it easy to avoid re-doing work a program has already done. The idea is to select a few key attributes of an object that can be used to decide if the object is the same as any of the objects that have already been processed - e.g., if a book has the same title and publication year as a book we've seen in the past, assume it's the same book and skip over it. If processing an individual object takes a lot of time and if your program is processing a lot of duplicates - maybe because a list is allowed to show duplicates or maybe because you're coming back and scraping a similar dataset multiple times - you can save a lot of time by adding skip blocks to your program.
But be careful - if you make assumptions about your data that turn out to be false, you might end up skipping too many objects. For instance, say you're scraping menu items and you assume each menu item will have a different description; if you use a skip block based on the item desription and then many menu items turn out to have an empty description, your program will process the first empty-description item but then skip over all the others. Take a look at the example below for an introduction to the questions you should consider when you're adding a skip block.
The situation:
You have a table of friends' names, ages, birthdays, phone numbers, and addresses. Unfortunately, you have collected this information several times as friends' information has changed over the years, so many friends have multiple rows in the table. You want a table that only lists each friend once, so you need to combine all the rows that refer to the same friend.
The goal is to find duplicates -- rows that refer to the same friend. You're going to do this by picking a set of important columns from the table. We'll use these columns to identify duplicates. If two rows have the same values in all of the selected columns, we'll merge the rows. If they don't, we'll assume they refer to two different people. When we merge two rows, it's ok to lose information from one of the merged rows -- we just want to make sure we have exactly one row per friend. You'll need to use your knowledge of what attributes tend to be unique about your friends. You'll also need to know what attributes tend to stay the same over time.
The data:
In this snippet of the table, the first two rows are from the same Alice at different points in time. Her birthday and phone number are the same, but she was 37 for one of the rows and 38 for another. The third and fourth rows refer to two different friends, both named Bob. We use a color to represent each friend -- blue for Alice, orange for the first Bob, purple for the second Bob.
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Alice | 38 | Feb 2, 1979 | 555-555-5555 | |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
Some good solutions
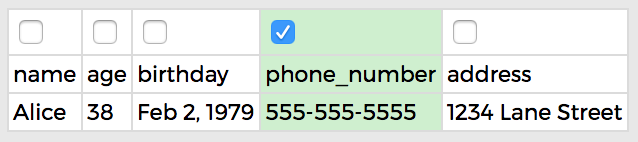
PHONE_NUMBER:
 |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Alice | 38 | Feb 2, 1979 | 555-555-5555 | |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
→ |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
You know all the rows include the phone number, and you know none of your friends share a phone number, so if you see a second row with a particular phone number, you know it refers to the same friend as the first row. You also know none of your friends have changed phone numbers since you started collecting their information (so Alice won't have a different phone number in her second row). You merge the Alice rows and keep both Bobs!
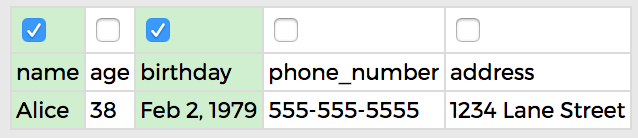
NAME AND BIRTHDAY:
 |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Alice | 38 | Feb 2, 1979 | 555-555-5555 | |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
→ |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
Alternatively, you know the Bobs have the same name, but not the same birthday, so you select the checkboxes for name and birthday. Even though Alice is in the table multiple times, her birthday won't change, so you merge the Alice rows and keep both Bobs!
Some bad solutions
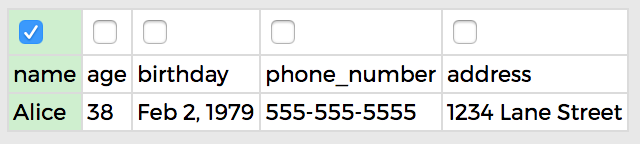
NAME:
 |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Alice | 38 | Feb 2, 1979 | 555-555-5555 | |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
→ |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
|
Just selecting
NAME doesn't work because although we successfully merge the two Alice rows that refer to a single friend, we also merge the two Bobs, even though they're different friends. Name doesn't work becuase a name can be shared by multiple friends.
The bad outcome: we got rid of a Bob!
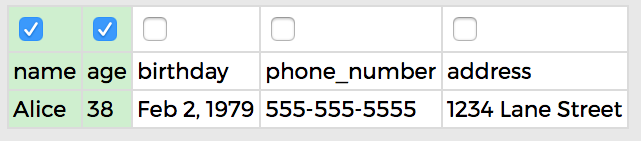
NAME AND AGE:
 |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Alice | 38 | Feb 2, 1979 | 555-555-5555 | |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
→ |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Alice | 38 | Feb 2, 1979 | 555-555-5555 | |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
Selecting
NAME AND AGE doesn't work because even though we now distinguish between between the two Bobs, we also distinguish between the two Alice rows, even though they refer to the same friend. Age changes over time, so this will prevent us from merging duplicates.
The bad outcome: we kept a fake Alice!
ADDRESS:
 |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Alice | 38 | Feb 2, 1979 | 555-555-5555 | |
| Bob | 37 | Jan 1, 1979 | 777-777-7777 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
→ |
| name | age | birthday | phone_number | address |
| Alice | 37 | Feb 2, 1979 | 555-555-5555 | 1234 Lane Street |
| Alice | 38 | Feb 2, 1979 | 555-555-5555 | |
| Bob | 38 | May 20, 1979 | 999-999-9999 | 9876 Drive Run |
|
Selecting
ADDRESS doesn't work because even though you know your friends all have different addresses, some rows don't include addresses -- in particular, one Bob row and one Alice row have the 'same' empty address, so they'll be merged. Columns where some rows won't have data can end up making all the rows without data look like duplicates.
The bad outcome: we eliminated a Bob by merging a Bob row with an Alice row!
Bear in mind that the right skip block for a given object might vary based on the task at hand. If you're collecting information about rental listings in your city and you want to collect exactly one listing per building (because you want to know how housing options are distributed geographically) you're probably fine making a skip block with just the address. On the other hand, if you're looking to track how landlords raise and lower the rent of a given apartment over time, using the address alone will cause you to discard all but the first instance of a given address. To track prices, you'll probably prefer to use both the address and the price, so that you'll get a new row every time the landlord lists a place with a changed price. And if there are multiple units at a given address, you'll have to add even more attributes, because you'll need to distinguish between multiple units at one address. So always consider your goals when you're deciding how to design your skip blocks.
Adding Skip Blocks
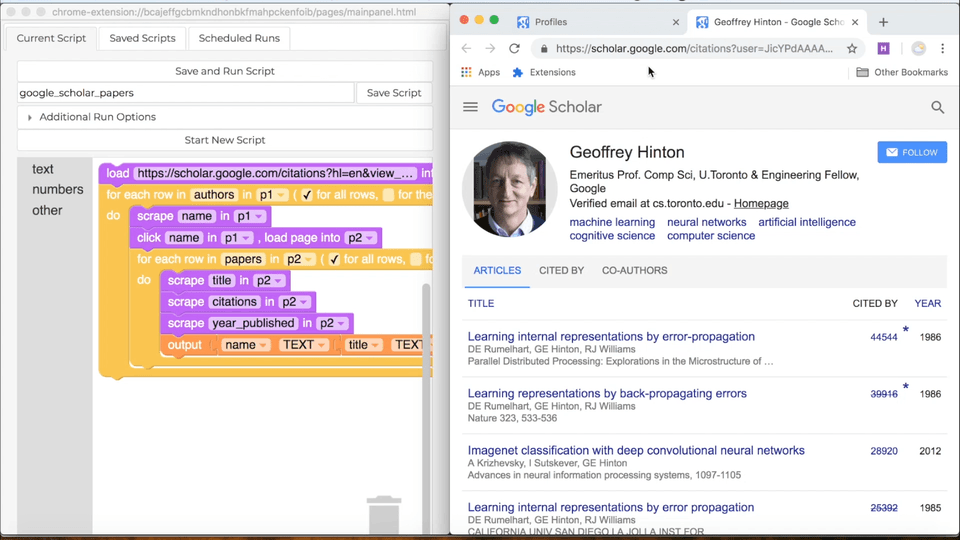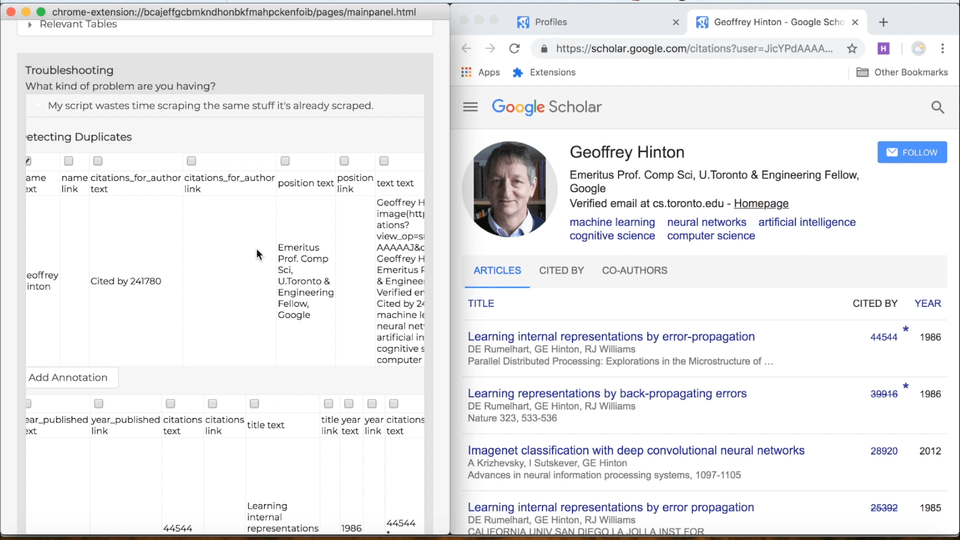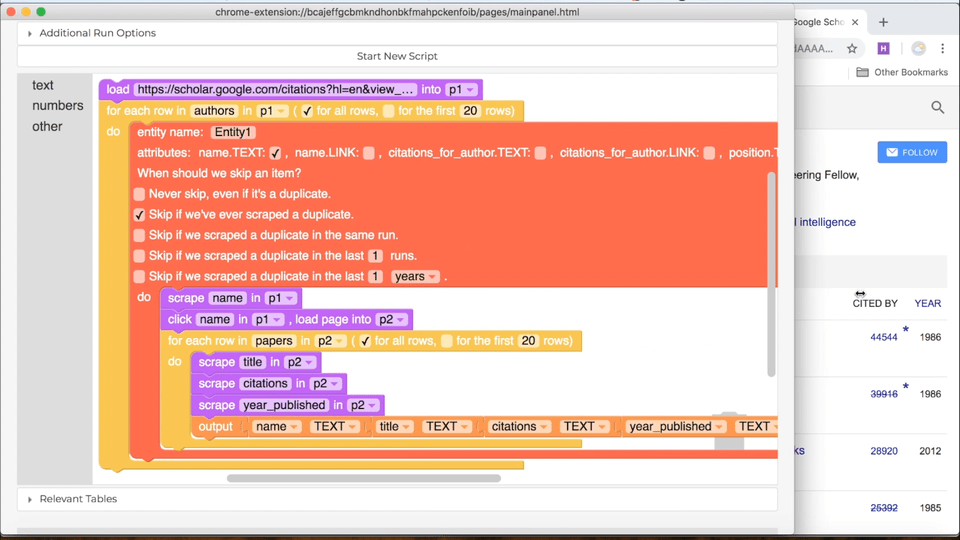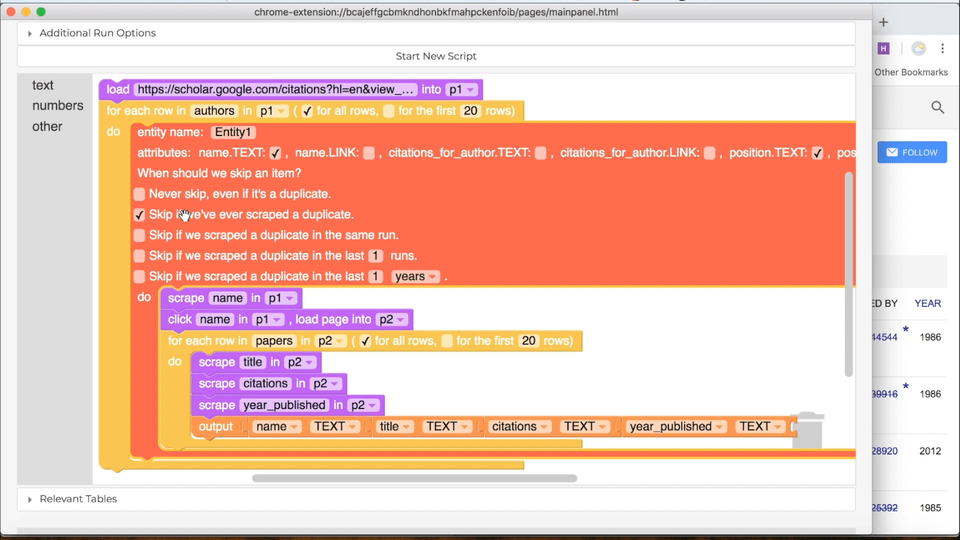
Now that you know how to design a skip block, here's how you add one to your own program. First, in the "Current Script" tab, scroll down to the "Troubleshooting" section and click on "My script wastes time scraping the same stuff it's already scraped." Now you'll see a set of tables, one for each table in your program. Each table will look like the ones in the examples above, with a checkbox for each column. Use the checkboxes to pick which attributes you'll use in your skip block. Once you're happy with the set of columns you've chosen, click the "Add Annotation" button below. You'll see a big red block appear in your Helena program. In the block, you'll be able to control when you skip objects. You have the option of: (i) never skipping (this is the same as not having a skip block), (ii) skipping if you've ever seen the object before, (iii) skipping only if you've seen the object already in the current run, (iv) skipping if you've seen it in the last few runs, or (v) skipping if you've seen it within a certain period of time. By default, it will skip over objects that have been seen at any point in the past.
Helena only starts tracking which objects it's seen once you run a version that includes a skip block. So if you've run your program without skip blocks in the past, adding a skip block won't cause the program to skip over objects that were scraped during pre-skip-block runs. However, all future runs will have the skipping behavior you specify.
Also note that if you rename and save your program, you're essentially creating a new program. The new program won't know about the objects that the original program scraped, so it won't skip over objects that the prior program scraped.
Here's how it looks in practice when you add a skip block:
← Resources